探究 block 数据结构及内存管理
本文首先将介绍一些 block 的基础, 随后着重介绍下面的内容
- block 的数据结构
- block 的内存管理(retain,release)
会用到下面这个
可编译的源码
基础
语法
Block 的语法比较难记, 以至于出现了 fuckingblocksyntax 这样的网站专门用于记录 block 的语法, 摘录如下:
作为变量
1 | returnType (^blockName)(parameterTypes) = ^returnType(parameters) {...}; |
作为属性
1 | @property (nonatomic, copy, nullability) returnType (^blockName)(parameterTypes); |
作为函数声明参数
1 | - (void)someMethodThatTakesABlock:(returnType (^nullability)(parameterTypes))blockName; |
作为函数调用中的参数
1 | [someObject someMethodThatTakesABlock:^returnType (parameters) {...}]; |
作为 typedef
1 | typedef returnType (^TypeName)(parameterTypes); |
捕获外部变量
block 可以捕获来自外部作用域的变量(id 类型, C++类型, 基础数据类型, block), 这是 block 一个很强大的特性
1 | - (void)foo { |
正常情况下, 捕获的外部变量在 block 里做的修改,在外部是不起作用的。如果想要在外部起作用,需要使用 __block 来声明变量:
1 | int __block anInteger = 42 |
所以,根据变量是否被 __block 修饰,可以将变量分为两类:
- by ref: 引用类型。该类的变量被 __block 修饰,在 block 内部对其修改,外部也生效
- by copy:拷贝类型。该类的变量不被 __block 修饰,在 block 内部对其修改,外部不生效(全局/静态 变量除外)
至于原因进阶部分会进行详细的探究
进阶
数据结构
运行下面的代码
1 | typedef void(^BLK)(void); |
打印结果为
1 | global = <__NSGlobalBlock__: 0x104bb22b0> |
在 iOS 平台中, 一共有三种类型的 block:
- _NSConcreteGlobalBlock: 在 .data 区域, block 内部没有访问任何的外部非(静态变量 && 全局变量)的变量(^{;}同样是该类型)
- _NSConcreteMallocBlock: 在堆中创建内存, 使用
__strong修饰的 block - _NSConcreteStackBlock: 在栈中创建内存, 使用
__weak修饰的 block 或者是匿名 block
优先级为 _NSConcreteGlobalBlock > _NSConcreteMallocBlock == _NSConcreteStackBlock,即满足 _NSConcreteGlobalBlock 条件的 block 就是 _NSConcreteGlobalBlock 类型的
_NSConcreteGlobalBlock 类型的 block 我不知道初始化的时候是否直接在 .data 区域创建。
_NSConcreteMallocBlock 和 _NSConcreteStackBlock类型的 block 在初始化时在栈中创建,随后如果有 __storng 强指针引用的话,
则进行 retain 操作,将其内存拷贝到堆中,后续的 retain 操作则只是增加 block 的引用计数
使用命令xcrun -sdk iphoneos clang -arch arm64 -rewrite-objc -fobjc-arc -fobjc-runtime=ios-13.0.0 YOUR_FILE_NAME将下面的代码转换成 C++ 实现
1 | - (void)foo |
转换得到的 C++ 实现, 只截取部分
1 | static void __Block_byref_id_object_copy_131(void *dst, void *src) { |
需要注意的是,上面生成的 C++ 代码中 block 的结构体,并不符合最新版本 objc4-779.1 源码里 block 的结构定义
在 objc4-779.1 里 block 结构体的定义如下:
1 | #define BLOCK_DESCRIPTOR_1 1 |
不是有三种类型的 BLOCK_DESCRIPTOR 结构体,只是根据功能将其分为三部分,其实是一个整体
注意下面两个结构体在内存上是完全一样的,原因是结构体本身并不带有任何额外的附加信息
1 | struct SampleA { |
Block_layout 成员变量介绍:
- void *isa: isa 指针
- int flags: 使用位域来保存信息, 例如引用计数, 是否正在被销毁等信息
- int reserved: 保留变量
- void (*invoke)(void *, …): 函数指针, 指向 block 实现函数的调用地址
- struct Block_descriptor *descriptor: block 的附加描述信息,一般来说都包含 Block_descriptor_1,但是是否包含 Block_descriptor_2 和 Block_descriptor_3 需要根据捕获外部变量的类型来判断
- 还有一些捕获的外部变量
| 位域名 | 位置 | 含义 |
|---|---|---|
| BLOCK_DEALLOCATING | 0x0001 | 1 表示正在被销毁 |
| BLOCK_REFCOUNT_MASK | 0xfffe | block 是引用计数 |
| BLOCK_NEEDS_FREE | 1 << 24 | 1 表示 block 已拷贝到堆中 |
| BLOCK_HAS_COPY_DISPOSE | 1 << 25 | block 是否有 copy/dispos 函数,即 descriptor 是否包含 Block_descriptor_2 |
| BLOCK_HAS_CTOR | 1 << 26 | copy/dispose helper 函数里面有 C++代码 |
| BLOCK_IS_GC | 1 << 27 | 1 表示使用 GC 管理内存,iOS 平台中不使用 GC |
| BLOCK_IS_GLOBAL | 1 << 28 | 1 表示是个全局 block |
| BLOCK_USE_STRET | 1 << 29 | arm64 架构下没用,不知道干嘛的 |
| BLOCK_HAS_SIGNATURE | 1 << 30 | 是否有函数类型编码 |
| BLOCK_HAS_EXTENDED_LAYOUT | 1 << 31 | GC 下使用 |
Block_descriptor 成员变量介绍:
- unsigned long int reserved: 预留变量
- unsigned long int size: block 结构体的 size 大小
- void (*copy)(void *dst, void *src): copy 函数,将 block 成员变量 从栈拷贝到堆中。后面会再介绍
- void (*dispose)(void *): dispose 函数, 对 block 成员变量内存回收
- const char *signature:函数的类型编码
- const char *layout: GC 下使用,不知道具体作用
让我们对照着 C++ 实现捋一遍,因为实现里的 block 结构体是老版本所以跟上面讲的可能会有出入
1 | struct __block_impl { |
在结构体 __TestObject__foo_block_impl_1 有很多捕获的外部变量充当的成员变量,如下所示
1 | int *staticInt; |
为了尽可能的谈论多的情况,在示例代码中我在 block 加了许多不同类型的外部变量
可以看到,全局/静态 变量和 __block 变量,都是将变量的地址保存在成员变量中,这样做的目的是为了在内部修改该变量在外部也会生效。
而其它非 __block 变量则仅仅拷贝了值,类似于浅拷贝
__Block_byref_byrefWeakObject_1 是 Block_byref 类型的结构体。__block 变量在编译时变成对应的 Block_byref 实例,且实例持有该变量
Block_byref 结构体的定义如下:
1 | struct Block_byref { |
类似 Block_descriptor,根据功能将其分为三部分
成员变量介绍:
- void *isa:一般指向 0x0,如果该变量还被 __weak 修饰,则指向 _NSConcreteWeakBlockVariable
- struct Block_byref *forwarding:指向该结构体。在拷贝到堆的过程中,在堆中新建一个结构体实例,此时栈中的实例并没有被销毁,将栈中实例 forwarding 指向堆中的实例
- int flags:引用计数使用的 bit 数目和位置与 block 相同,其它不再介绍
- int size:Block_byref 结构体的字节长度
- void (*byref_keep)(struct Block_byref *dst, struct Block_byref *src):Block_byref 的 copy 函数,帮助将实例持有的变量拷贝到堆中
- void (*byref_destroy)(struct Block_byref *):Block_byref 的 dispose 函数,帮助将持有的变量销毁
- const char *layout:Block_byref 持有的变量
为了方便,后面将 Block_layout 的 copy/dispose 函数简称为 Block copy/dispose 函数; Block_byref 的 byref_keep/byref_destroy 函数简称为 __block copy/dispose 函数
在 foo() 函数中我们在 block 捕获了两个 __block 修饰的变量,下面是其中一个的 Block_byref 结构体
1 | struct __Block_byref_byrefObject_0 { |
编译时,编译器会将 __block 修饰的变量 byrefObject,转换成对应的 Block_byref 结构体 __Block_byref_byrefObject_0 实例,然后让实例持有该变量NSObject *__strong byrefObject;
block 结构体 __TestObject__foo_block_impl_1 里面还定义了一个初始化方法:
1 | _TestObject__foo_block_impl_1(void *fp, struct __TestObject__foo_block_desc_1 *desc, int *_staticInt, NSObject *__strong _commonObject, NSObject *__weak _weakObject, __strong BLK _blockObject, __Block_byref_byrefWeakObject_1 *_byrefWeakObject, __Block_byref_byrefObject_0 *_byrefObject, int flags=0) : staticInt(_staticInt), commonObject(_commonObject), weakObject(_weakObject), blockObject(_blockObject), byrefWeakObject(_byrefWeakObject->__forwarding), byrefObject(_byrefObject->__forwarding) { |
- 其中类似
: commonObject(_commonObject)的写法是将形参NSObject *__strong _commonObject赋值给成员变量_commonObject - 参数 flags 有一个默认值 0, 在本例中传入的值为 570425344, 用二进制表示为 0b00100010000000000000000000000000,即第 30 位(BLOCK_USE_STRET), 第 26 位(BLOCK_HAS_COPY_DISPOSE) bit 的值 1
- 参数 fp 是函数指针, 在本例中它的实现如下:
1 | static void __TestObject__foo_block_func_1(struct __TestObject__foo_block_impl_1 *__cself) { |
也就是 block 里面的代码。
可以看到非 __block 变量后面都写了注释 bound by copy,__block 变量后面的注释是 bound by ref,__block 变量都会转换成 Block_byref 实例保存在 block 中
为了方便,后面将 __block 修饰的变量称为引用变量,否则称为拷贝变量
- block 初始化参数 desc 的类型是
__TestObject__foo_block_desc_1 *
结构体的定义如下:
1 | static struct __TestObject__foo_block_desc_1 { |
并且初始化了一个结构体实例 __TestObject__foo_block_desc_1_DATA,其中 reserved 的值为 0, Block_size 的值为结构体 __TestObject__foo_block_impl_1 的字节长度
copy 和 dispose 两个函数指针分别指向函数 __TestObject__foo_block_copy_1 和 __TestObject__foo_block_dispose_1
实现如下:
1 | static void __TestObject__foo_block_copy_1(struct __TestObject__foo_block_impl_1*dst, struct __TestObject__foo_block_impl_1*src) {_Block_object_assign((void*)&dst->commonObject, (void*)src->commonObject, 3/*BLOCK_FIELD_IS_OBJECT*/);_Block_object_assign((void*)&dst->byrefWeakObject, (void*)src->byrefWeakObject, 8/*BLOCK_FIELD_IS_BYREF*/);_Block_object_assign((void*)&dst->weakObject, (void*)src->weakObject, 3/*BLOCK_FIELD_IS_OBJECT*/);_Block_object_assign((void*)&dst->byrefObject, (void*)src->byrefObject, 8/*BLOCK_FIELD_IS_BYREF*/);_Block_object_assign((void*)&dst->blockObject, (void*)src->blockObject, 7/*BLOCK_FIELD_IS_BLOCK*/);} |
这两个函数很容易看懂,有多少捕获的外部变量,就调用多少次 _Block_object_assign() 和 _Block_object_dispose() 函数。
需要注意的是 _Block_object_assign() 的第三个参数,根据变量的类型不同传入不同的标记,后面会详细讲
与其类似的是 Block_byref 的 copy/dispose 函数
在本例中它们的实现如下:
1 | static void __Block_byref_id_object_copy_131(void *dst, void *src) { |
可以看到,Block_byref 的 copy/dispose 函数最终也是调用 _Block_object_assign/_Block_object_dispose 函数
至于参数为什么要强转成 char*, 我的理解是这样的:
举个例子,定义一个 int 类型的数组, int a[10]。我们可以使用指针来代替数组的下标, 例如用(int *)a + 1来表示数组的第二个元素, 其距离第一个元素偏移了 4 个字节长度,所以强制转换成 char* 类型是为了每次偏移 1 个字节。上面的代码表示偏移了 40 个字节
而老版本 Block_byref 的定义(因为 C++ 实现符合源码)
1 | struct Block_byref { |
Block_byref 偏移 40 个字节后的位置刚好是持有变量的首地址,所以在这里传入的参数即是引用变量(被 __block 修饰的变量)
至于后面的数字 131 后面再讲
好了,数据结构就分析到这啦。
目前我们可以知道的是,block 以及 __block 变量在编译时会生成对应的 Block_layout,Block_byref 结构体,它们都有各自的 copy/dispose 函数
验证 block 数据结构
这一节主要使用 lldb 用来验证 block 的数据结构
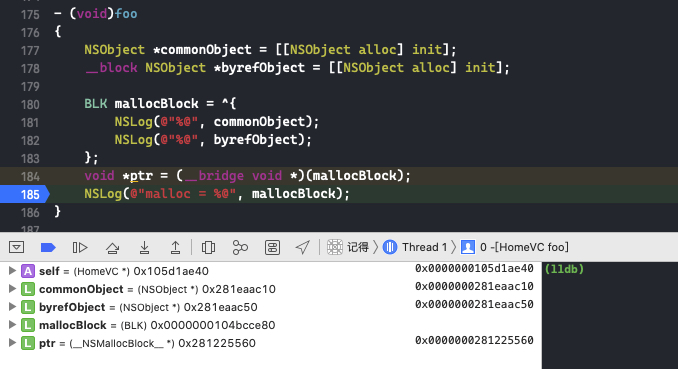
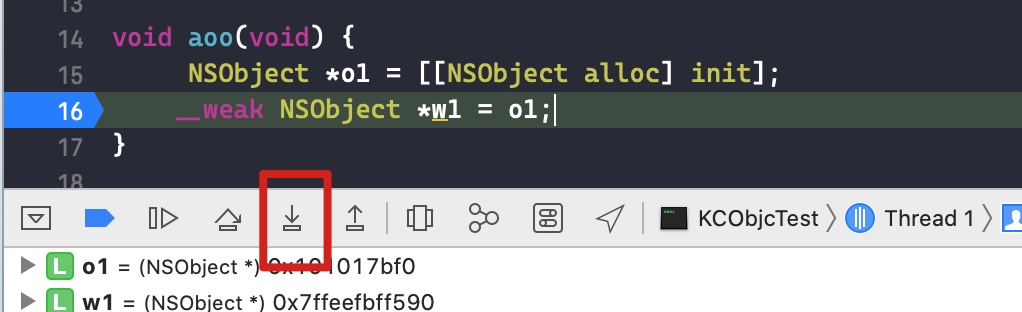
打个断点,使用命令 x/8xg ptr

根据上一节 block 结构体内容,我们可以知道各成员变量的值
| block 成员变量 | 值 |
|---|---|
| void *isa | 0x00000001ca53c0f0 |
| volatile int32_t flags | 0xc3000002 |
| int32_t reserved | 0x0 |
| void (*invoke)(void *, …) | 0x0000000104bcce80 |
| struct Block_descriptor_1 *descriptor | 0x000000010519e290 |
| 捕获变量 _commonObject | 0x0000000281eaac10 |
| Block_byref * _byrefObject | 0x0000000281225170 |
验证一下:

isa 指针指向 __NSMallocBlock__,没问题
flags 用二进制表示为 0b11000011000000000000000000000010,即位域 BLOCK_HAS_SIGNATURE,BLOCK_HAS_EXTENDED_LAYOUT,BLOCK_HAS_COPY_DISPOSE,BLOCK_NEEDS_FREE 为 1 引用计数 BLOCK_REFCOUNT_MASK 为 1
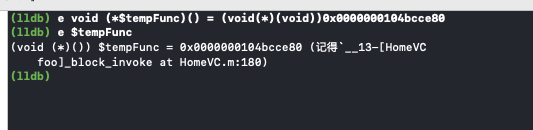
可以通过上面的方法打印出函数指针的内容
成员变量 _commonObject 的值于 commonObject 相同,均为 0x0000000281eaac10,说明是浅拷贝
下面来验证 descriptor
0x000000010519e290 为 Block_descriptor_1 结构体的首地址
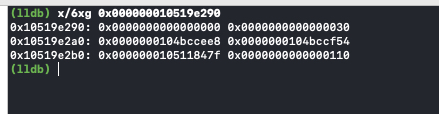
| Block_descriptor 成员变量 | 值 | 解释 |
|---|---|---|
| uintptr_t reserved | 0x0 | 预留字段 |
| uintptr_t size | 0x0000000000000030 | 十进制为 48,即 block 结构体的字节长度 |
| void (*copy)(void *dst, const void *src) | 0x0000000104bccee8 | copy 函数指针 |
| void (*dispose)(const void *) | 0x0000000104bccf54 | dispose 函数指针 |
| const char *signature | 0x000000010511847f | 函数类型编码 |
| const char *layout | 0x0000000000000110 | 不知道干嘛的 |
打印下 block 函数的类型编码
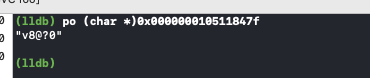
成员变量 const char *layout 应该是在 GC 下使用的,具体作用不明白
接下来验证 Block_byref 的结构
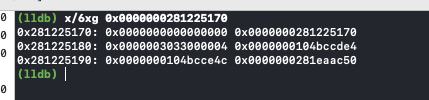
| Block_byref 成员变量 | 值 | 解释 |
|---|---|---|
| void *isa | 0x0 | isa |
| struct Block_byref *forwarding | 0x0000000281225170 | 十进制为 48,即 block 结构体的字节长度 |
| volatile int32_t flags | 0x33000004 | 标记,二级制表示为 0b00110011000000000000000000000100 |
| uint32_t size | 0x00000030 | Block_byref 结构体长度 |
| byref_keep | 0x000000010511847f | __block copy 函数指针 |
| byref_destroy | 0x0000000000000110 | __block dispose 函数指针 |
| const char *layout | 0x0000000281eaac50 | 持有的变量 byrefObject |
flags 表示引用计数为 2,因为初始化有一个,然后 block 有一个。位域 BLOCK_BYREF_LAYOUT_STRONG 为 1,表示该变量是 __strong 类型
const char *layout 表示其持有的变量
如何将 block 从栈拷贝到堆中
现在我们来探究一下 block 是如何从栈中拷贝到堆中的吧。
除 global block 类型的 block 均在栈中创建,当被强引用,即 retain block 的话,block 就会从栈拷贝到堆中,如果已经在堆中,则增加其引用计数
step into
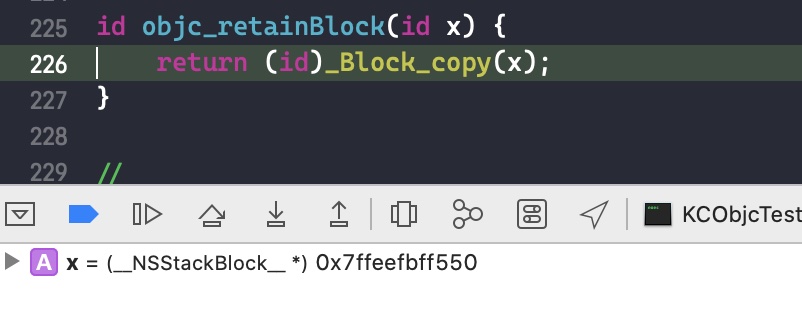
_Block_copy 的函数实现在 clang-800 源码 中可以看到
1 | void *_Block_copy(const void *arg) { |

我们主要看红色框框里面的代码:
- 首先通过
malloc()在堆中新建一个 block 结构体实例,接着使用memmove()将旧实例的数据拷贝过去 - 重置新实例成员变量 flags 的 BLOCK_REFCOUNT_MASK(引用计数)部分
- 将新实例成员变量 flags 的位域 BLOCK_NEEDS_FREE 设置为 1, 表示该 block 在堆中
- 将新实例的 isa 指向 _NSConcreteMallocBlock
- 如果存在 Block copy 函数,则调用
上一节中已经提到过,这里再贴一下它的实现:
1 | static void __TestObject__foo_block_copy_1(struct __TestObject__foo_block_impl_1*dst, struct __TestObject__foo_block_impl_1*src) |
需要注意的是,如果外部变量是 C++类型,则不会调用
_Block_object_assign()函数,而是其对应的 const 拷贝构造方法。注释如下:
In these cases helper functions are synthesized by the compiler for use in Block_copy and Block_release, called the copy and dispose helpers. The copy helper emits a call to the C++ const copy constructor for C++ stack based objects and for the rest calls into the runtime support function _Block_object_assign. The dispose helper has a call to the C++ destructor for case 1 and a call into _Block_object_dispose for the rest.
_Block_object_assign函数的实现如下:
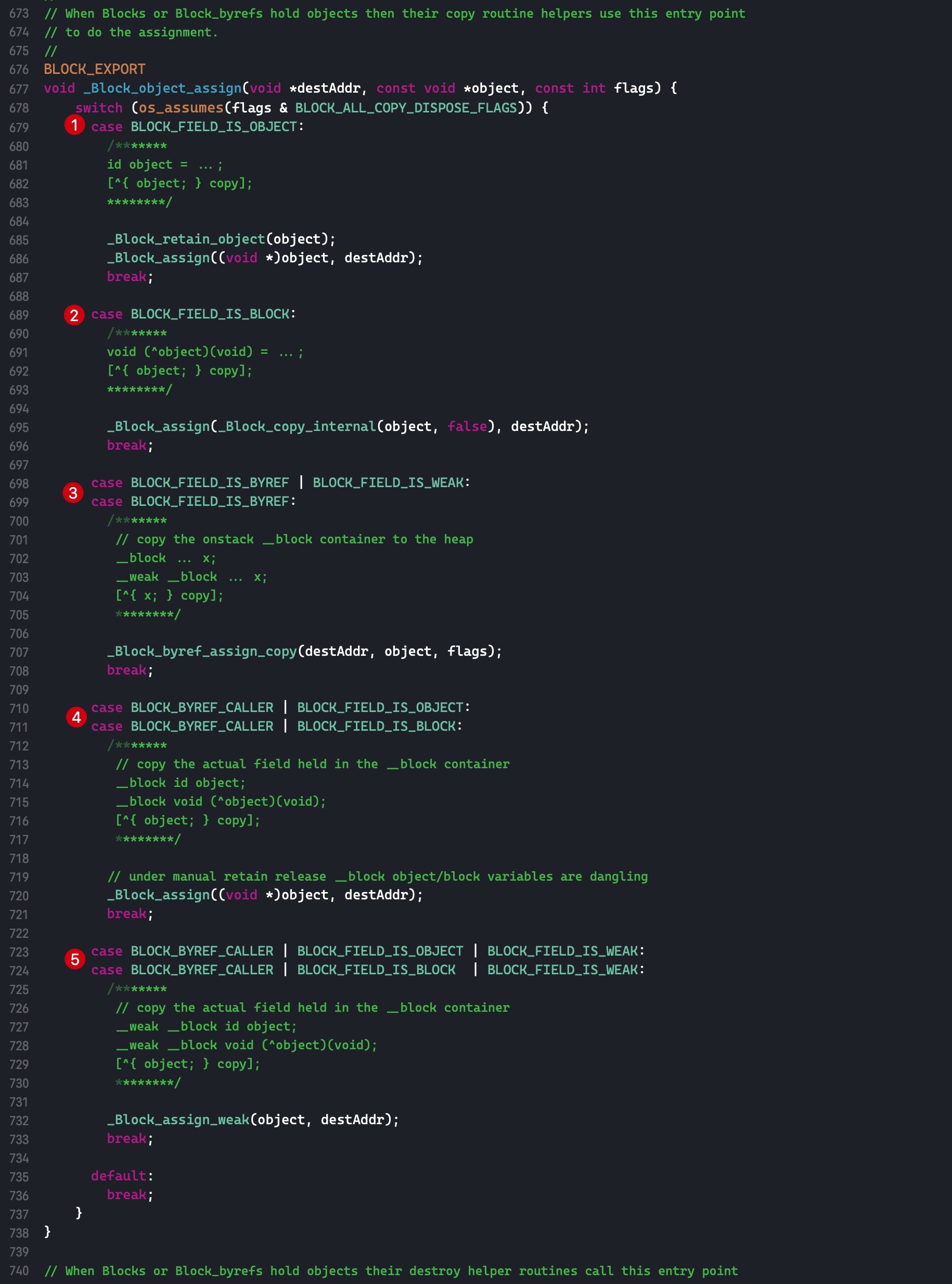
参数 flags 有以下几种情况:
由 Block copy 函数调用:
id 3(^Block) 7
- __block 8
__weak __block 8+16
flags 有 4 种可能: 3, 7, 8, (8+16)
由 __block copy 函数调用:
BLOCK_BYREF_CALLER (128):表示由 __block copy 调用
此时, 传入的 flags 有 4 种可能:
__block id 128+3__block (^Block) 128+7
- __weak __block id 128+3+16
__weak __block (^Block) 128+7+16
总共有以上 8 种情况
需要注意的是,Block copy 调用该函数,第一个参数是指针的地址(void **),第二个参数传入的是指针的值(void *)
而 __block copy 调用该函数,传入的前两个参数均为指针的值(void *)
下面根据 case 条件分几步来讲解这个函数:
- 代码块 1:
Block copy 函数调用,且该变量是 id 类型的
代码_Block_retain_object()最终会调用下面这个函数
1 | static void _Block_retain_object_default(const void *ptr) { |
代码_Block_assign()最终会调用下面这个函数
1 | static void _Block_assign_default(void *value, void **destptr) { |
不知道调用 _Block_retain_object 函数的目的是什么
这一分支仅做了浅拷贝,拷贝指针内容
- 代码块 2:
Block copy 函数调用,且该变量也是一个 block
这里首先调用了 _Block_copy_internal() 函数, 先将 block 类型的变量拷贝到堆中
然后调用 _Block_assign 将其堆中的地址赋值给 Block 对应的成员变量
- 代码块 3:
Block copy 函数调用,且变量被 __block 修饰
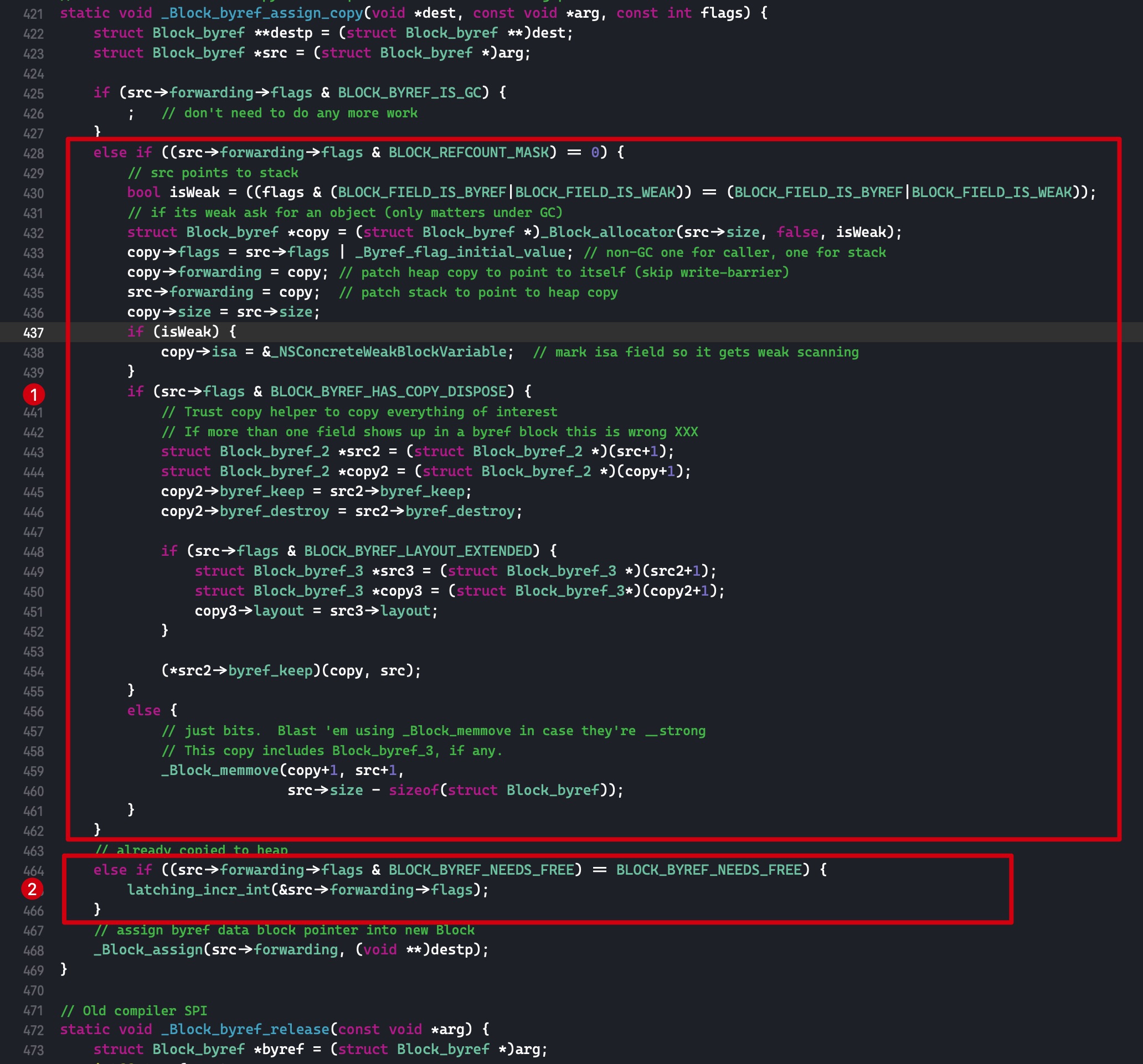
这里传入的第一个参数 void *dest 表示的是指针的地址
_Block_byref_assign_copy 实现中代码块 1 的逻辑如下
- 声明一个布尔值 isWeak, 用来表示该变量是否还被 __weak 修饰
- _Block_allocator 函数最终调用
malloc()函数, 在堆上拷贝一份同样内存大小的 Block_byrefs 实例 - 将旧实例的成员变量 flags 拷贝到新实例中, 并将新实例的引用计数设置为 2。 1 份是因为栈上有一个实例, 1 份是因为堆上也有一个, 1+1 就等于 2 了
- 将旧实例和新实例的成员变量 forwarding 均赋值为新实例
- 如果 isWeak 为 true, 则将 Block_byrefs 实例的 isa 指针指向 _NSConcreteWeakBlockVariable
- 如果实例有
__block copy/dispose helpers(还是调用 _Block_object_assign 函数), 则调用它对实例持有的变量进行拷贝到堆操作; 如果没有的话则将旧实例中 size 后面的成员变量拷贝到新实例的 bit 中
函数里面有一行看起来比较让人困扰的代码
1 | struct Block_byref_2 *src2 = (struct Block_byref_2 *)(src+1); |
在前面的声明中,src 被声明成了 Block_byref * 类型,所以 src + 1 的意思是从 src 的首地址偏移 sizeof(Block_byref) 个字节,即 Block_byref_2 的首地址
结构体拷贝完成后,随后将 Block_byref 持有的变量通过函数 *src2->byref_keep 也拷贝到堆中
_Block_byref_assign_copy 实现中代码块 2 的作用是如果 Block_byref 持有的变量已经拷贝到堆中了, 则增加其引用计数
- 代码块 4:
__block copy 函数调用,且持有的变量不被 __weak 修饰
最终会调用下面那个函数
1 | static void _Block_assign_default(void *value, void **destptr) { |
浅拷贝
- 代码块 5:
__block copy 函数调用,且持有的变量被 __weak 修饰
最终会调用下面那个函数:
1 | static void _Block_assign_weak_default(const void *ptr, void *dest) { |
这里讲一下我的理解:
void * 是一个指针,里面保存了一个地址,但是我们不能 *(void *) 这样使用它,因为我们不知道它指向的结构是什么类型的。如果要使用的话就需要将其转换成其它类型,例如 int *,所以在这里可以仅仅把它看成是变量,保存了一个地址。
而 void **,其表示指向指针的指针,不同于 void *,我们可以 *(void **) 这样使用它,因为我们知道 void ** 指向的内容是一个指针。
在 _Block_assign_weak_default 函数中,我们先将 dest 强转成 void ** 类型,然后就可以对其进行赋值操作啦
至此,整个拷贝流程已经讲的差不多了,这里总结一下:
- 一个 block 可能捕获多个外部变量
- block 在栈中生成,retain 后,将栈中的内容拷贝到堆中
- block 会调用
Block copy函数,对其捕获的变量也进行拷贝操作- 如果是 C++ 类型,则调用其 const 拷贝构造函数到堆中
- 如果是 block 类型,则将其拷贝到堆中
- 如果是 id 类型,因为已经在堆中了,所以进行浅拷贝,仅复制指针值
- 如果是 __block 修饰的变量,则将其对应的 Block_byref 结构体拷贝到堆中,随后调用 __block copy 函数将其持有的变量也拷贝到堆中
如何销毁 block
这一节我们将探究如何销毁 block
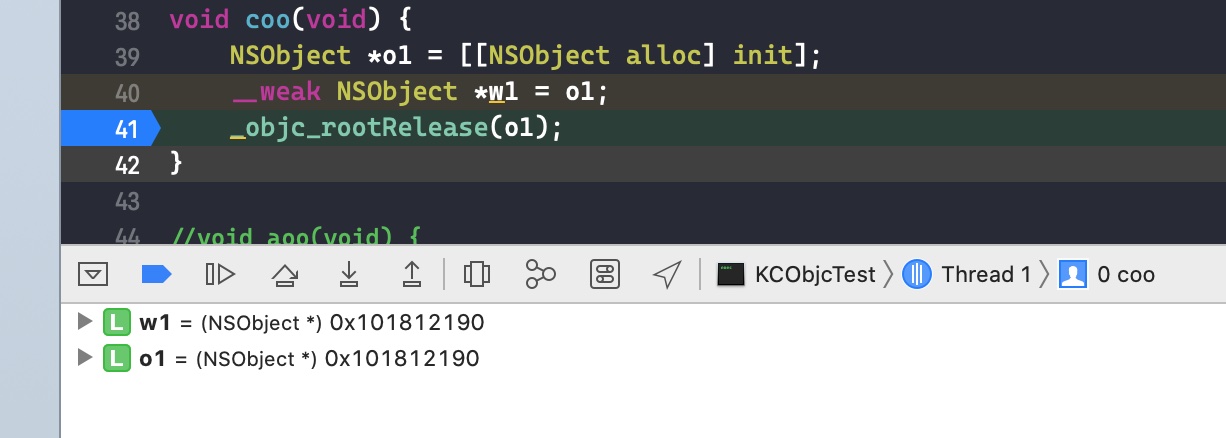
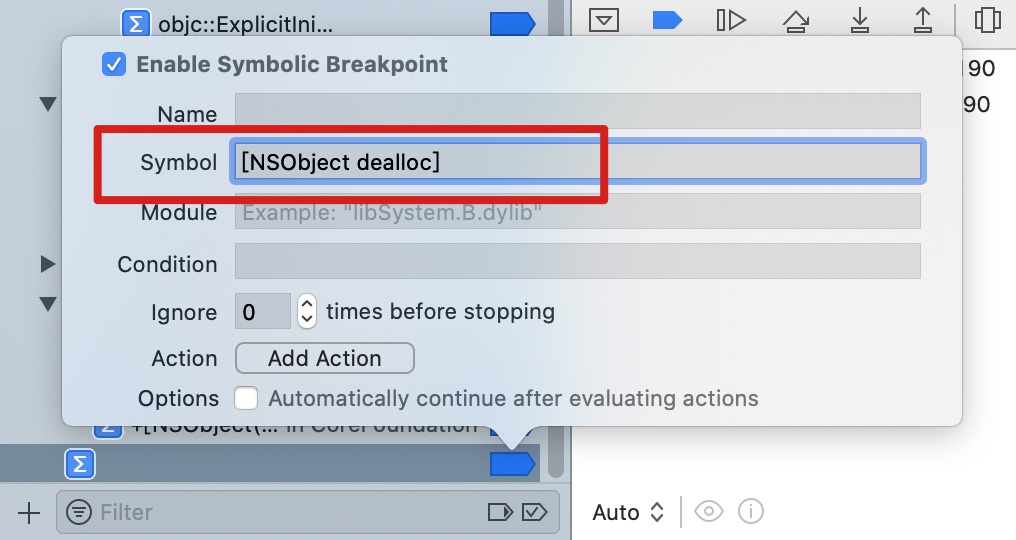
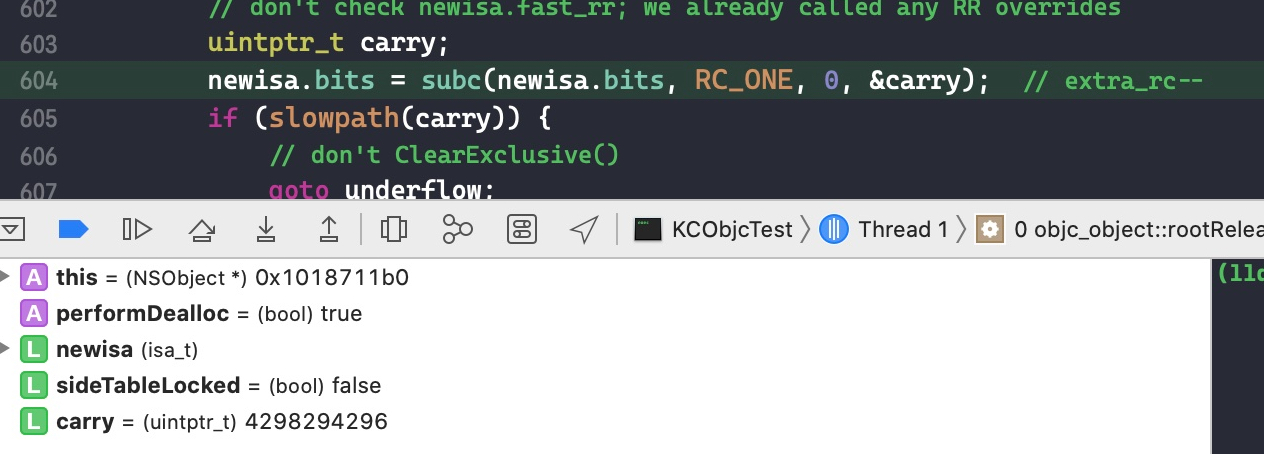
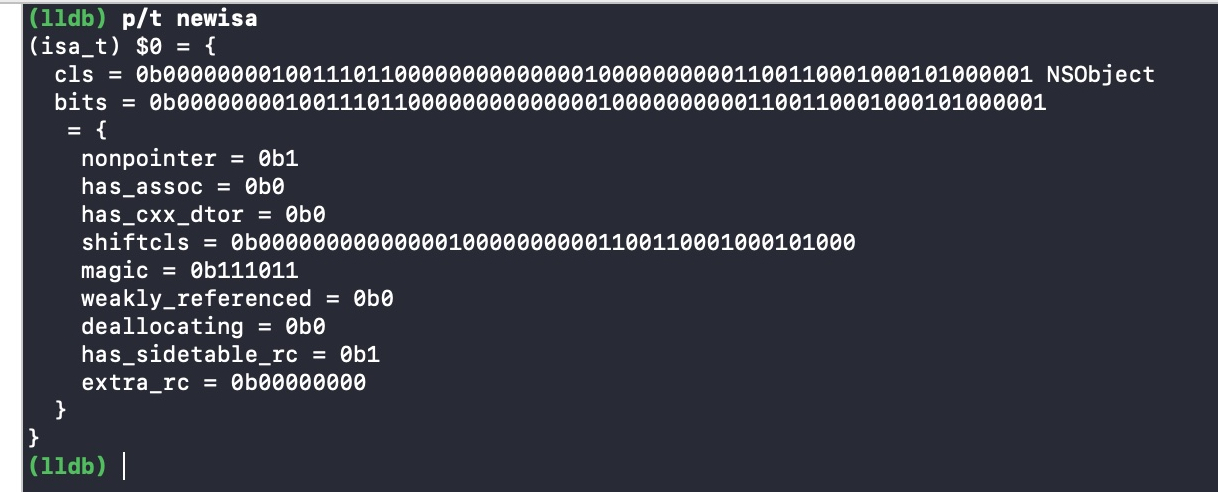
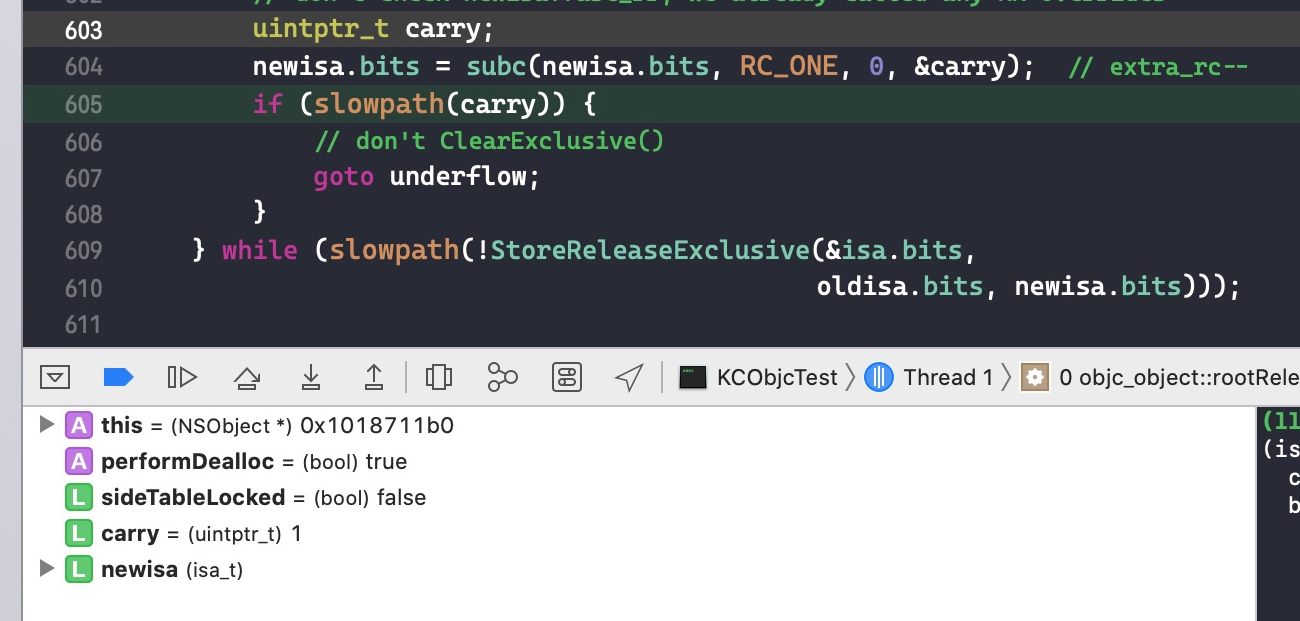
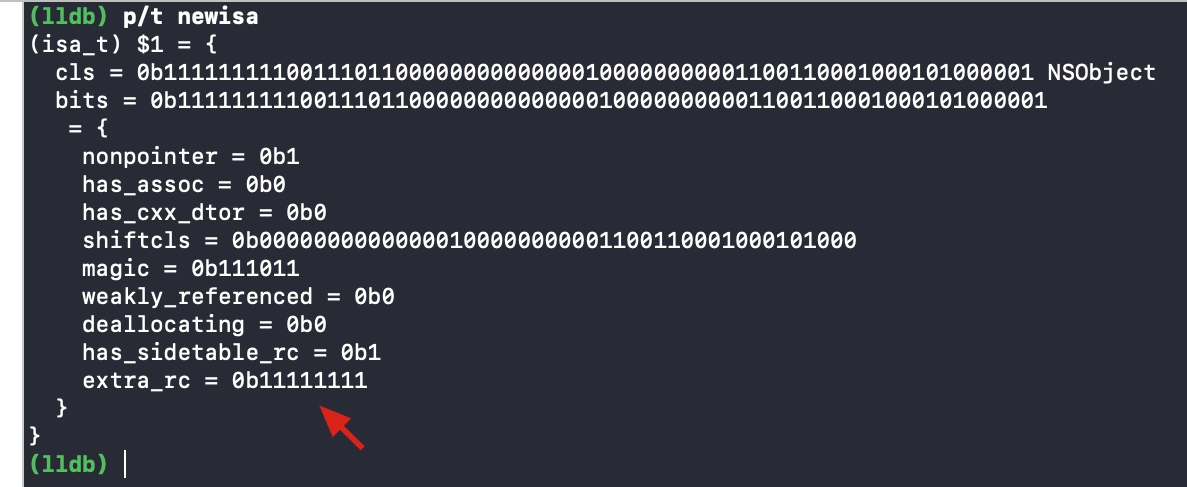
创建一个 malloc block 类型的 block,foo() 结束,block 会被回收。
在函数尾巴那里打个断点
step into
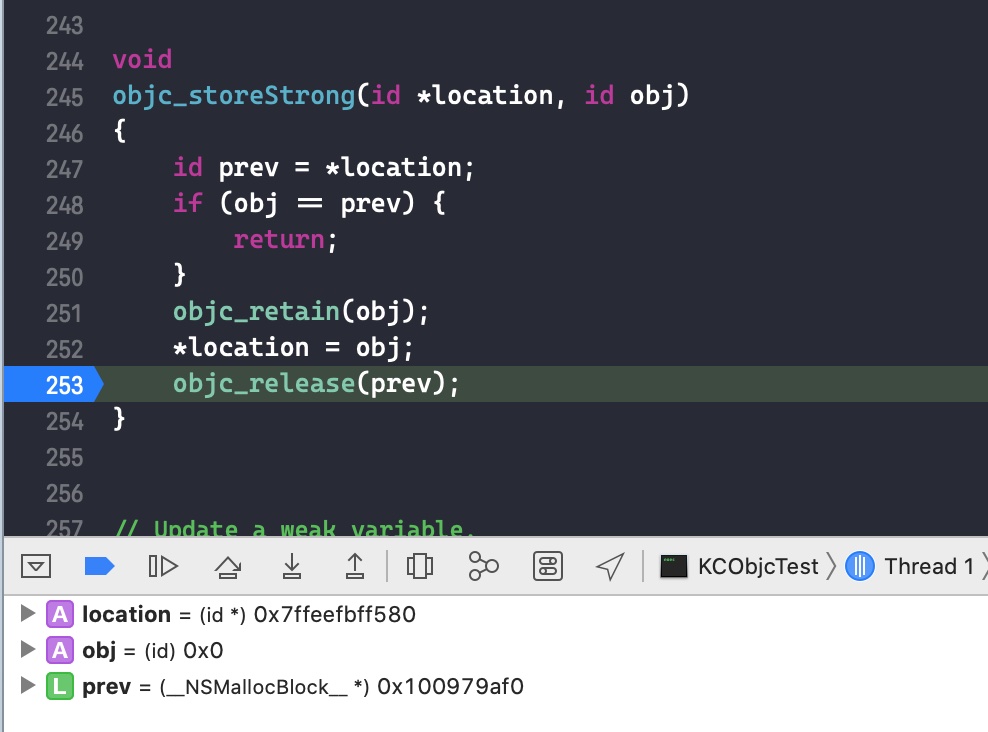
将断点停留在objc_release()函数
runtime 通过该函数对 block 进行 release 操作,如果其引用计数变成 0,则销毁
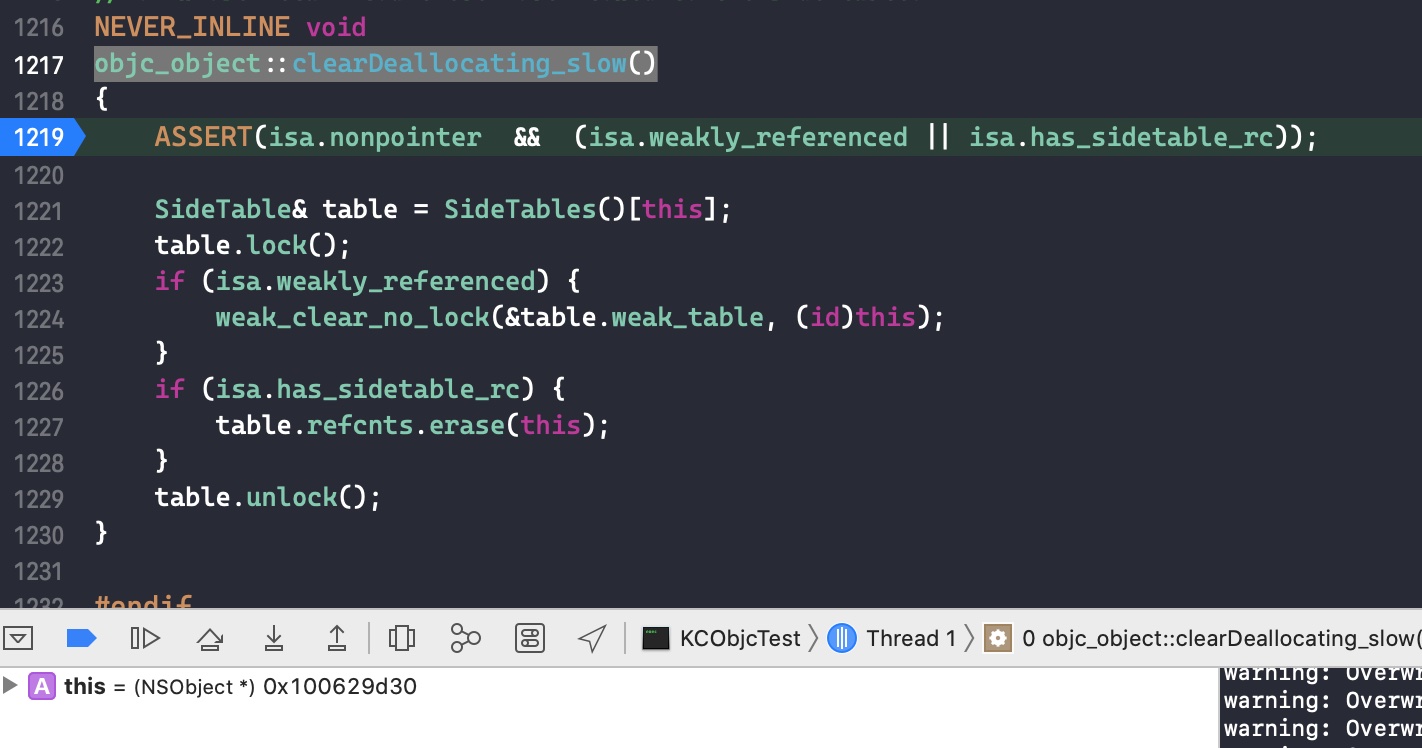
继续 step into
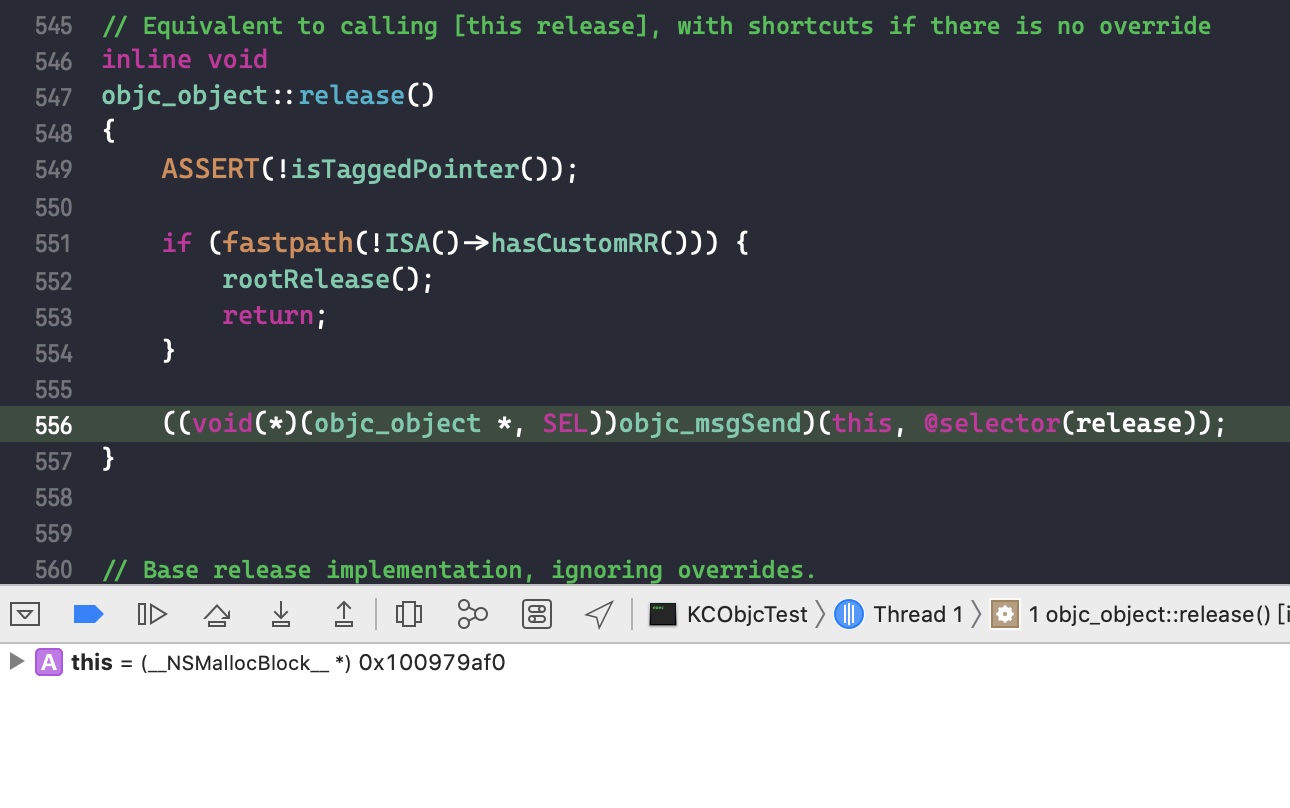
block 是特殊的类,自己重写了release()函数,所以代码 ISA()->hasCustomRR() 返回的结果是 true,将执行自己重写的 release() 函数
继续 step into
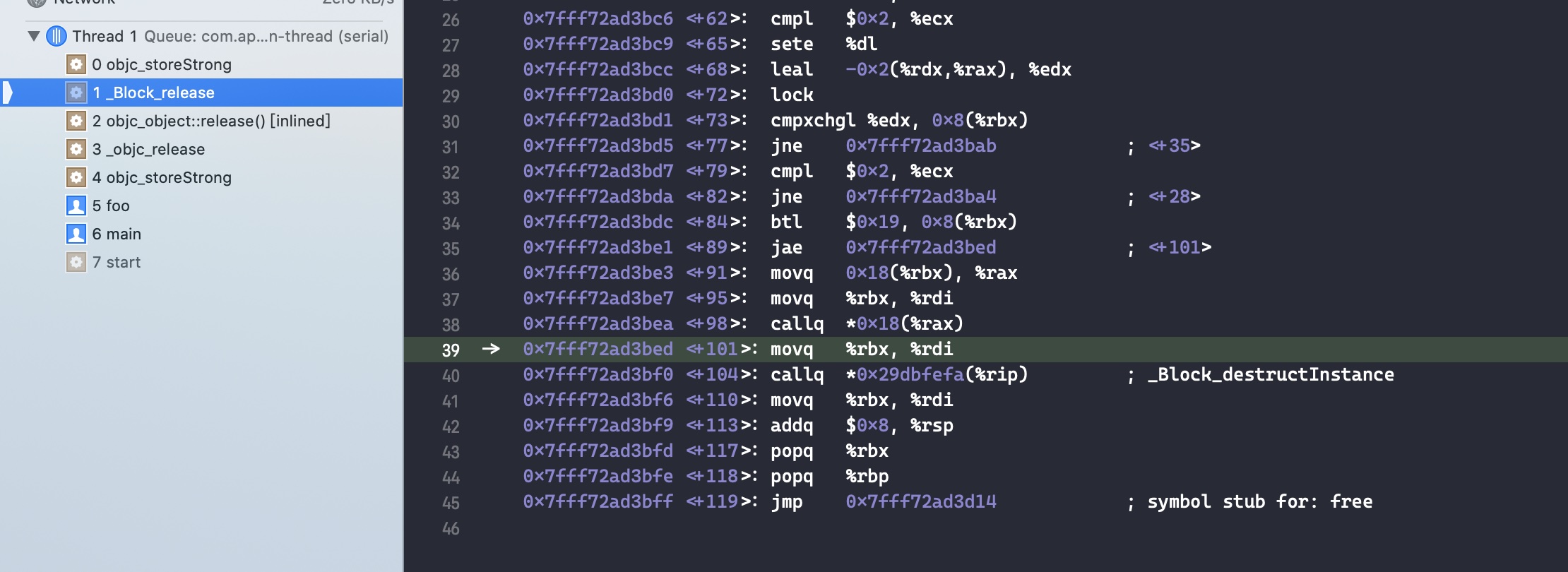
因为没有 block 的 release()源码,通过调用栈发现随后调用了 _Block_release() 函数
在可编译的源码中可以找到该函数的实现(直接在文件夹中搜索)
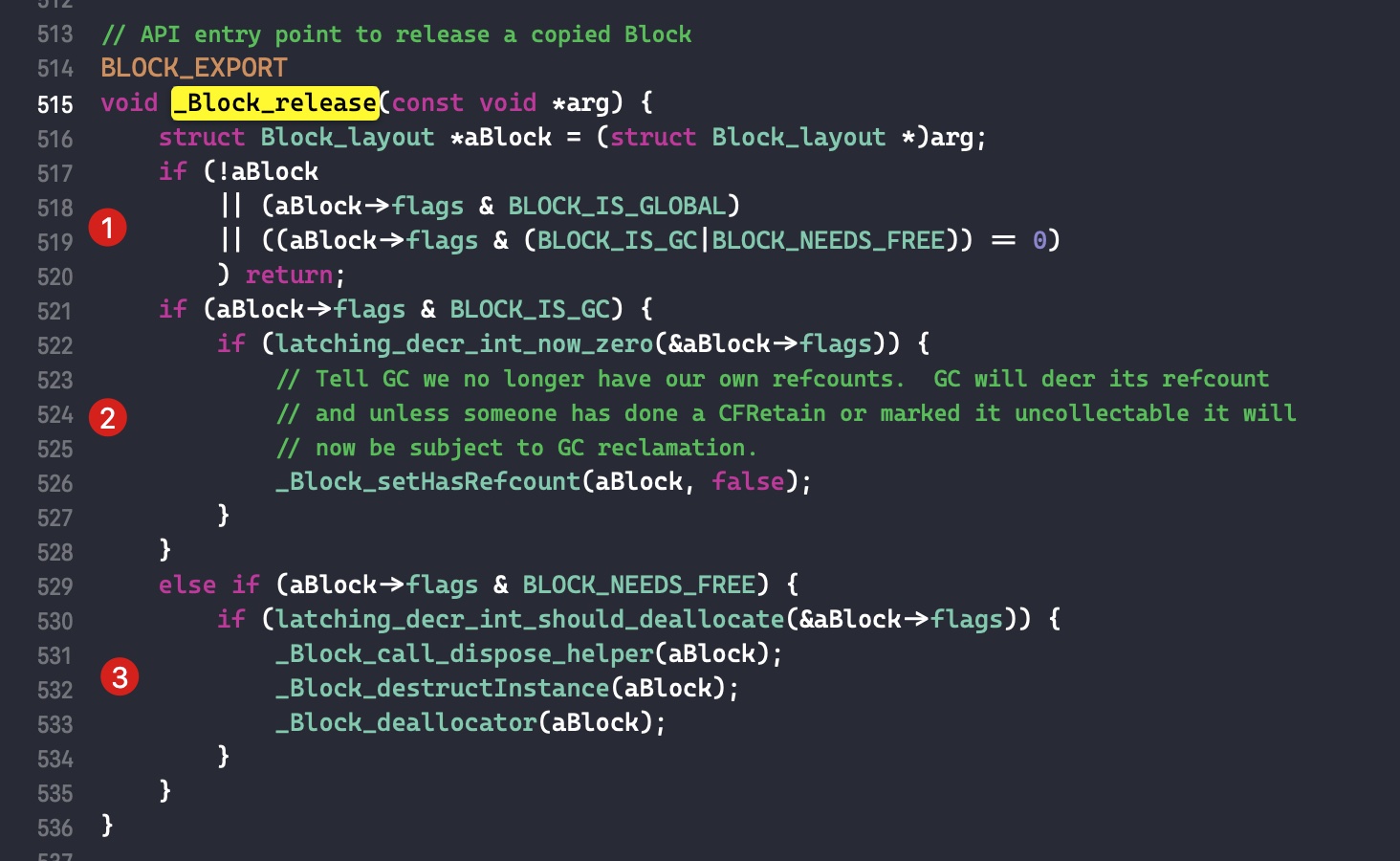
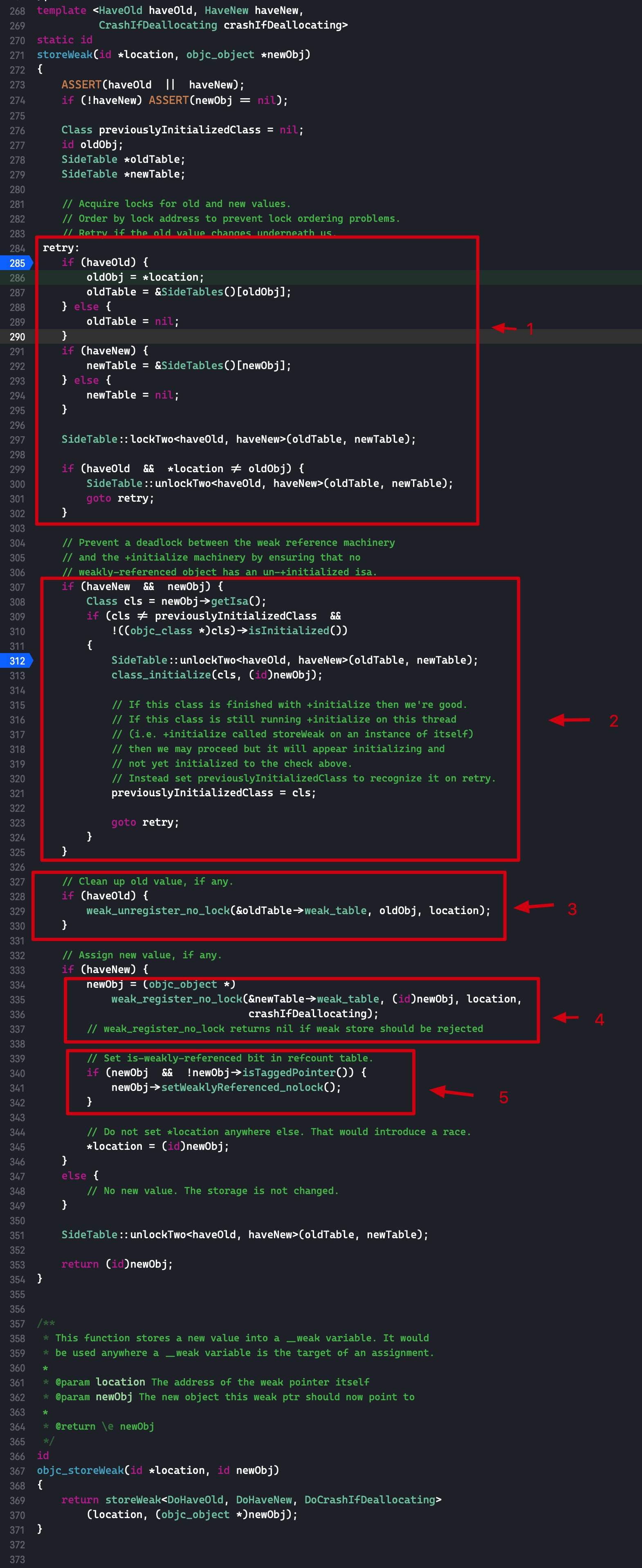
根据 if 的判断将函数分为三个部分
- 判断条件 1:如果是全局 block 或者其引用计数已经为 0(表示已经在销毁了), 则返回
- 判断条件 2:如果使用 GC 管理内存,则执行什么什么操作。因为 iOS 平台不使用 GC,所以略过
- 判断条件 3:如果 block 已经在堆上了,则将其引用计数减 1,如果减为 0,则调用下面三个函数
1 | _Block_call_dispose_helper(aBlock); |
- 第一个函数
_Block_call_dispose_helper
在同个文件中搜索该函数,其实现如下
1 | static void _Block_call_dispose_helper(struct Block_layout *aBlock) |
如果存在 Block dispose 函数,则调用
1 | static void __TestObject__foo_block_dispose_1(struct __TestObject__foo_block_impl_1*src) |
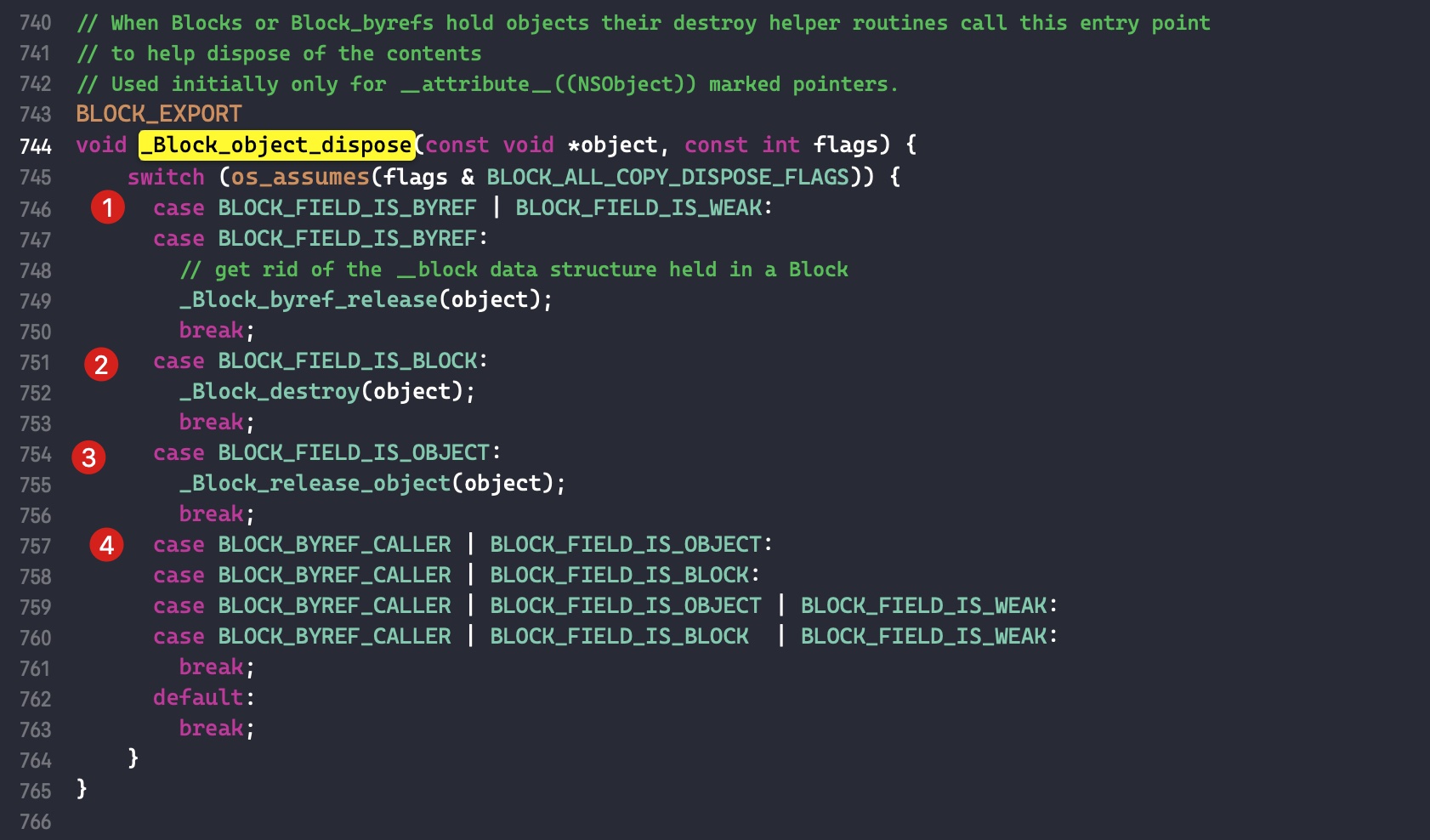
通过判断条件将 _Block_object_dispose 分为几部分
- 判断条件 1:变量由 __block 修饰
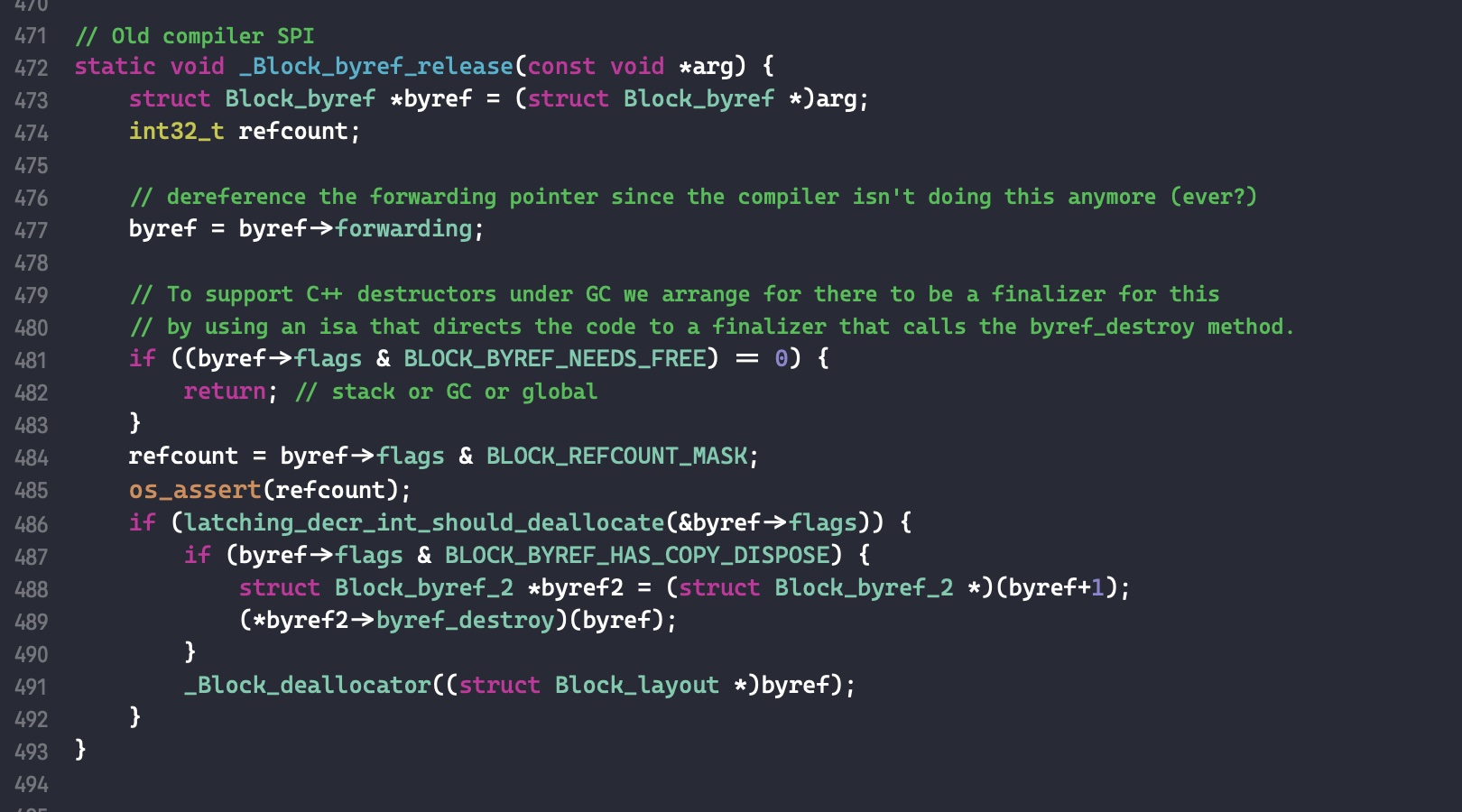
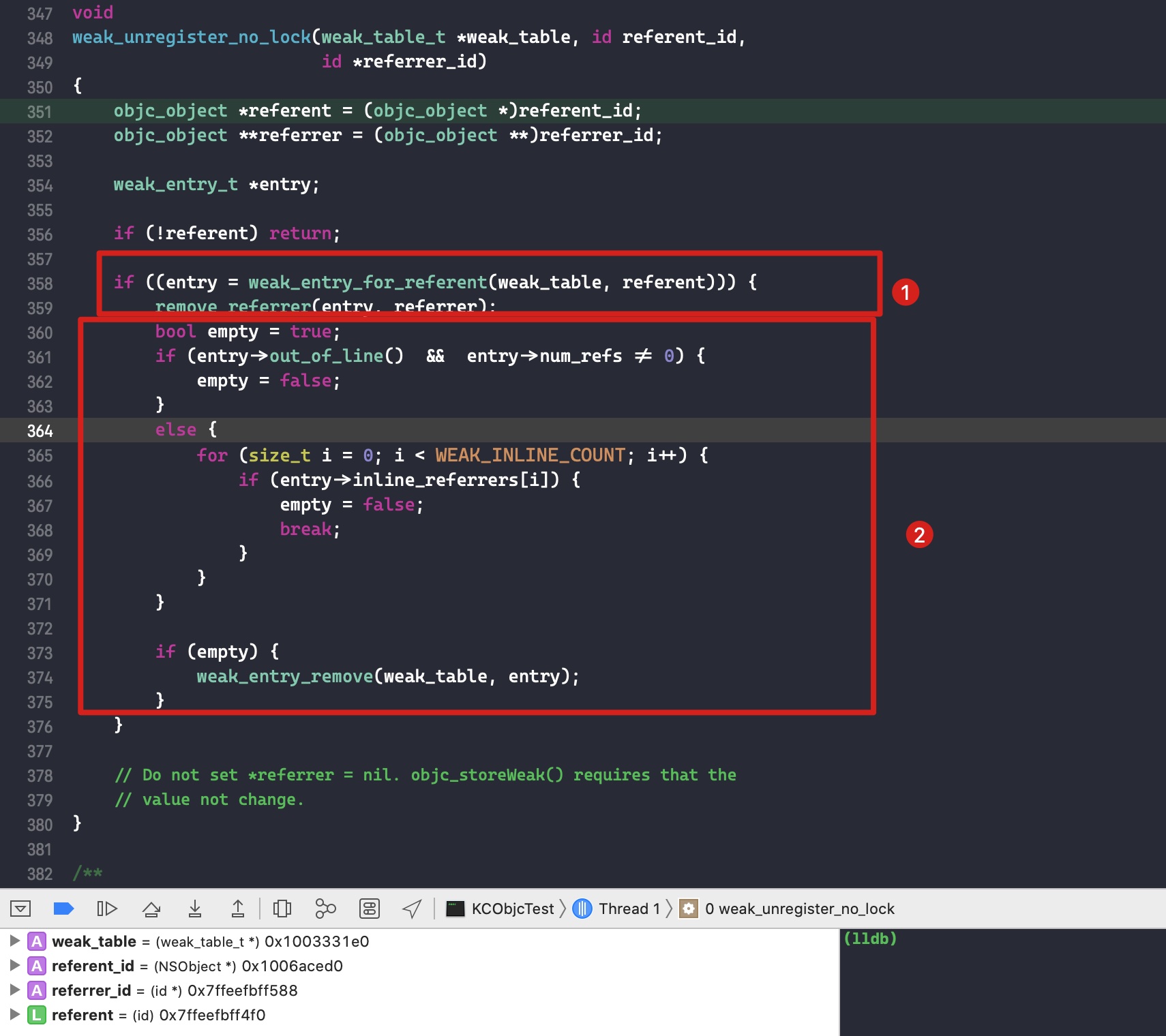
代码byref = byref->forwarding;,因为可能会有 byref 在栈中,而 forwarding 此时却在堆中的情况。随后判断 byref 是否在栈中,如果是的话则立即返回。
对 Block_byref 的引用计数减 1 随后判断是否为 0,如果是的话则调用其 byref_destroy 函数(也就是 _Block_object_dispose),销毁其持有的变量
最后将 Block_byref 结构体的内存释放掉
- 判断条件 2:变量是 Block 类型

调用 _Block_release 来销毁该 block
- 判断条件 3:变量是 id 类型
_Block_release_object 最终调用的函数如下
1 | static void _Block_release_object_default(const void *ptr) { |
等于什么都没做,这是因为 id 类型的对象由 ARC 管理其内存。即不再被强指针引用时引用计数减 1
- 判断条件 4
什么都没做,如果走到走一步说明可能系统有异常
接着讲 block 销毁时调用的第二个函数 _Block_destructInstance。
调试时,调用栈里也有这个函数

接着 step into
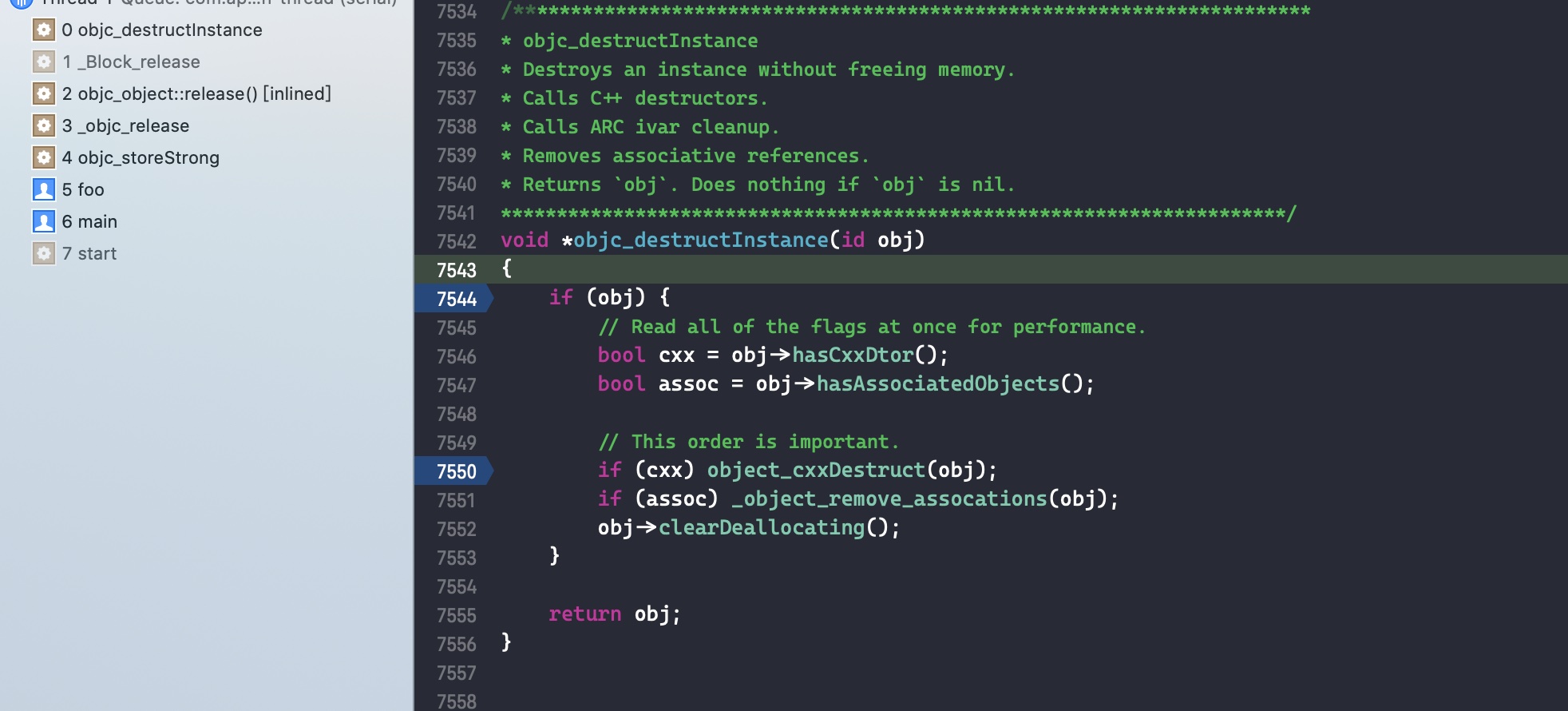
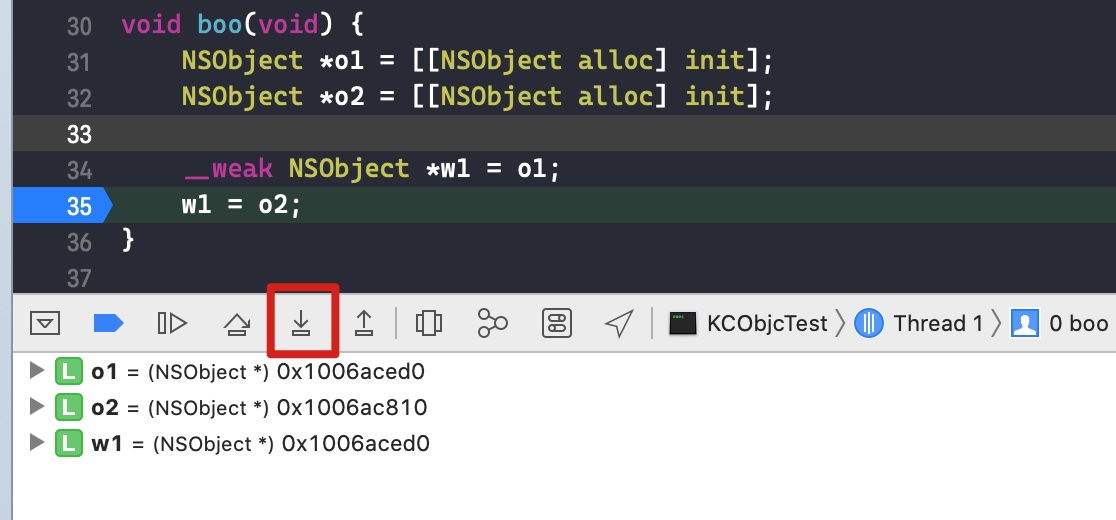
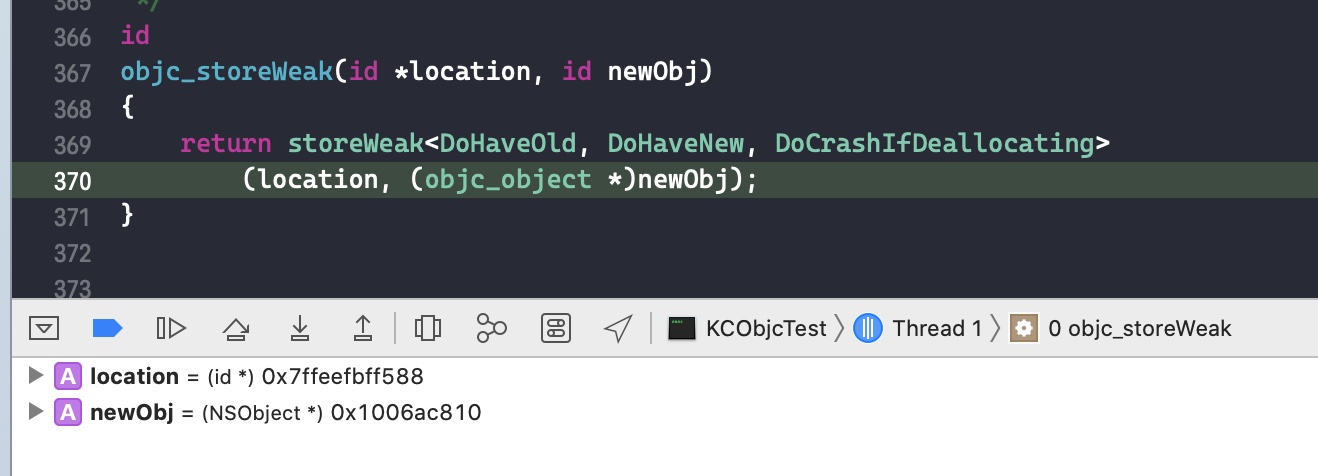
使用该函数,主要是为了将在弱引用表中注册的使用 __weak 引用 block 的变量置为 nil,因为 block 已经要被销毁了
这里不仔细讲了
最后调用 _Block_deallocator() 函数,将 block 结构体的内存销毁
这里总结一下 block 的内存销毁流程:
- 先将 block 捕获的外部变量进行销毁
- 将弱引用 block 的指针置为 nil
- 将 block 结构体的内存销毁