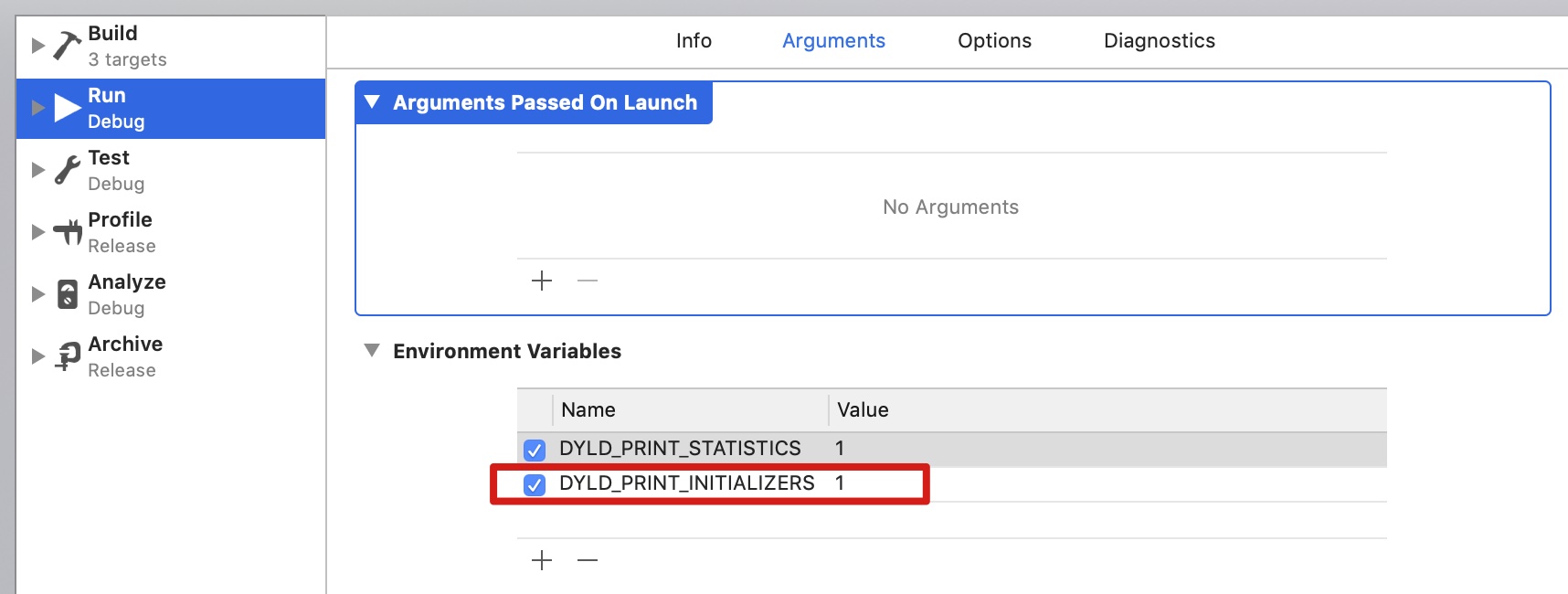
extern "C" { extern Class objc_debug_taggedpointer_classes[_OBJC_TAG_SLOT_COUNT]; extern Class objc_debug_taggedpointer_ext_classes[_OBJC_TAG_EXT_SLOT_COUNT]; }
内置类型数组的数目为 8,使用高 2 - 高 4 的 3 个 bit 来存储数据
扩展类型数组的数目为 256,,使用高 5 - 高 12 的 8 个 bit 来存储数据
是否剩余的 bit 都用来保存数据了呢?答案是否定的,拿 NSUmber 举个例子,它属于内置类型,其 tagged pointer 额外使用 低 1 - 低 4 的 5 个 bit 用来保存数字的类型信息,即使用 56 个 bit 来保存数据。
- (void)boo { NSNumber *a = [NSNumber numberWithInt:1]; NSNumber *b = [NSNumber numberWithInt:2]; NSNumber *c = [NSNumber numberWithInt:16]; NSLog(@"pointer a is %lx", a); NSLog(@"pointer b is %lx", b); NSLog(@"pointer c is %lx", c); NSLog(@"pointer d is %lx", d); }
输出结果:
1 2 3
pointer a is ef59c3d36981ed4b pointer b is ef59c3d36981ed7b pointer c is ef59c3d36981ec5b
NSLog(@"pointer a real value is %lx", ((uintptr_t)a ^ objc_debug_taggedpointer_obfuscator)); NSLog(@"pointer b real value is %lx", ((uintptr_t)b ^ objc_debug_taggedpointer_obfuscator)); NSLog(@"pointer c real value is %lx", ((uintptr_t)c ^ objc_debug_taggedpointer_obfuscator)); }
输出结果:
1 2 3
pointer a real value is b000000000000012 pointer b real value is b000000000000022 pointer c real value is b000000000000102
- (void)foo { NSNumber *d = [NSNumber numberWithLongLong:-0x7FFFFFFFFFFFFF]; NSLog(@"pointer a real value is %lx", ((uintptr_t)d ^ objc_debug_taggedpointer_obfuscator)); }
NSLog(@"pointer a real value is %lx", ((uintptr_t)a ^ objc_debug_taggedpointer_obfuscator)); NSLog(@"pointer b real value is %lx", ((uintptr_t)b ^ objc_debug_taggedpointer_obfuscator)); NSLog(@"pointer c real value is %lx", ((uintptr_t)c ^ objc_debug_taggedpointer_obfuscator)); NSLog(@"pointer d real value is %lx", ((uintptr_t)d ^ objc_debug_taggedpointer_obfuscator));
输出结果
1 2 3 4
pointer a real value is b000000000000012 pointer b real value is b000000000000021 pointer c real value is b000000000000014 pointer d real value is b800000000000013
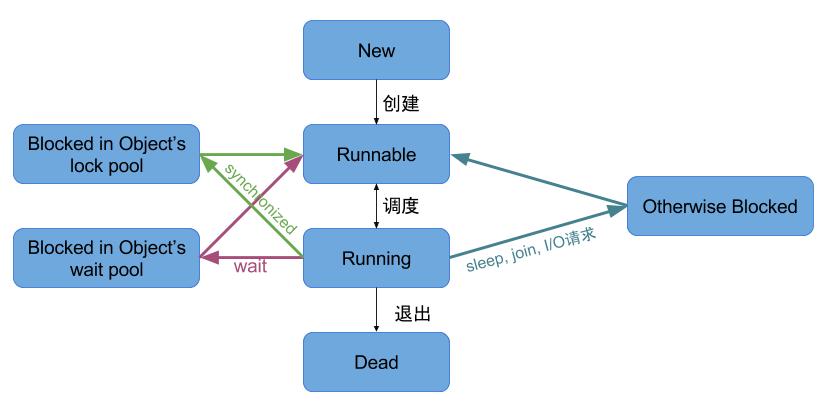
时间片又称为“量子”或者“处理器片”,是分时操作系统分配给每个正在运行的进程微观上的一段 CPU 时间。现代操作系统(例如 Windows,Mac OS X)允许同时运行多个进程。例如,在打开音乐播放器的同时用浏览器浏览网页并下载文件。由于有些计算机只有一个CPU,所以不可能真正地同时运行多个任务。这些进程“看起来像”同时运行,实则是轮番运行,由于时间片通常很短(在Linux上为5ms-800ms),用户不会感觉到。
在 JYSqlModel 中,一个 model 对应于一个表。首先,你需要给这个表确定好一个名字,所以你必须在 model 内重载 JYSqlModel 的类方法+ (nonnull NSString *)tbName;。注意这个名字不能重复重复。 系统会在启动的时候,会根据 model 结构创建相应的表。表中字段(column)与 model 属性是一一对应的,在默认情况下,字段名字即是属性名字,当然你也可以使用协议中的方法自定义字段名,这个后面会详细讲。字段的类型会根据属性的类型分成不同的类型,目前只支持下表中的几种类型:
在项目更新中,如果我们需要增加、删除 model 中的某些属性,或者改变属性的类型要怎么办呢? 很简单,你只需要对 model 进行修改,在项目运行时,JYSqlMode 会检测新 model 的结构以及旧表的结构,来判断是否需要进行数据迁移。 所谓的数据迁移也就是,将旧表重命名,根据新 model 的结构新建一个表,然后将旧表的数据迁移到新的表中。如此操作之后,新表的结构与新 model 的结构就一一对应了,保证了你在执行增删改查操作时不会出错。
YYClassInfo 保存了 Class 的绝大部分信息,但是 objc 是一门动态的语言,可以在运行时添加方法,属性等信息,这也意味着 YYClassInfo 里面保存的信息可能不是最新的。所以当你对 Class 做了一些修改之后,你需要先获得该 Class 对应的 YYClassInfo实例,然后手动调用- (void)setNeedUpdate;来刷新保存在缓存中的 info 信息。
if (meta->_isCNumber) { NSNumber *num = YYNSNumberCreateFromID(value); ModelSetNumberToProperty(model, num, meta); if (num) [num class]; // hold the number }
这个比较简单。首先将从json字典得到的value进行处理,得到一个 NSNumber 类型的数据 num。然后将 num 转换成相应类型的数据,通过objc_msgSend消息发送赋值给该属性。由于在赋值的函数中参数的类型是__unsafe_unretained(类似weak),所以需要在赋值成功前持有该数据,否则程序会因为 num 成为野指针而崩溃,所以在ModelSetNumberToProperty后面还有这样一行代码if (num) [num class];,看似没用,其实还是有点用的。如果你想对__unsafe_unretained了解深一点可以看孙源的这篇博客
然后时属性属于 Foundation 类型时,会先将 value 转换成属性的类型meta->_nsType,然后通过objc_msgSend赋值给属性。 当属性属于数组(NSArray, NSMutableArray)和字典(NSDictionary, NSMutableDictionary)时复杂一点:
dylib的二进制数据会随机的映射到内存的一个随机地址ASLR(Address space layout randomization,)中,这个随机的地址跟代码和数据指向的旧地址(preferred_address)会有一定的偏差,dyld需要修正这个偏差(slide),做法就是将dylib内部的指针地址都加上这个偏移值,偏移值的计算方法如下:
static ALWAYS_INLINE id callAlloc(Class cls, bool checkNil, bool allocWithZone=false) { if (slowpath(checkNil && !cls)) return nil;
#if __OBJC2__ if (fastpath(!cls->ISA()->hasCustomAWZ())) { // No alloc/allocWithZone implementation. Go straight to the allocator. // fixme store hasCustomAWZ in the non-meta class and // add it to canAllocFast's summary if (fastpath(cls->canAllocFast())) { // No ctors, raw isa, etc. Go straight to the metal. bool dtor = cls->hasCxxDtor(); id obj = (id)calloc(1, cls->bits.fastInstanceSize()); if (slowpath(!obj)) returncallBadAllocHandler(cls); obj->initInstanceIsa(cls, dtor); return obj; } else { // Has ctor or raw isa or something. Use the slower path. id obj = class_createInstance(cls, 0); if (slowpath(!obj)) returncallBadAllocHandler(cls); return obj; } } #endif
// No shortcuts available. if (allocWithZone) return [cls allocWithZone:nil]; return [cls alloc]; }
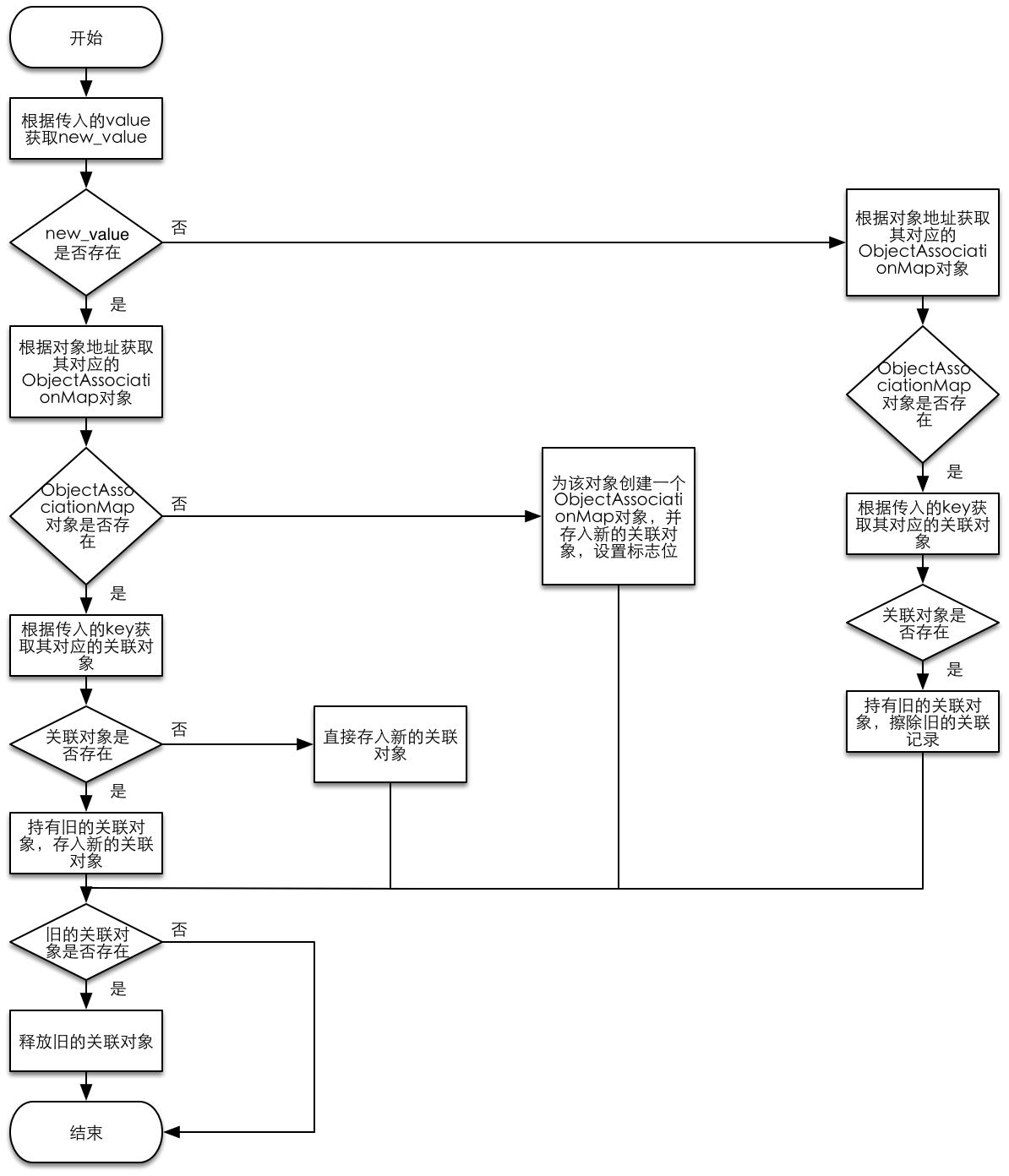
void _object_remove_assocations(id object) { vector< ObjcAssociation,ObjcAllocator<ObjcAssociation> > elements; { AssociationsManager manager; AssociationsHashMap &associations(manager.associations()); if (associations.size() == 0) return; disguised_ptr_t disguised_object = DISGUISE(object); AssociationsHashMap::iterator i = associations.find(disguised_object); if (i != associations.end()) { // copy all of the associations that need to be removed. ObjectAssociationMap *refs = i->second; for (ObjectAssociationMap::iterator j = refs->begin(), end = refs->end(); j != end; ++j) { elements.push_back(j->second); } // remove the secondary table. delete refs; associations.erase(i); } } // the calls to releaseValue() happen outside of the lock. for_each(elements.begin(), elements.end(), ReleaseValue()); }
其实不看代码应该也能够猜出个大概了吧.
根据 object地址 找到映射的 refs,遍历 refs,将保存着的 value 保存在 vector< ObjcAssociation,ObjcAllocator<ObjcAssociation> > elements
void *objc_destructInstance(id obj) { if (obj) { // Read all of the flags at once for performance. bool cxx = obj->hasCxxDtor(); bool assoc = !UseGC && obj->hasAssociatedObjects(); bool dealloc = !UseGC;
// This order is important. if (cxx) object_cxxDestruct(obj); if (assoc) _object_remove_assocations(obj); if (dealloc) obj->clearDeallocating(); } return obj; }
void _object_remove_assocations(id object) { vector< ObjcAssociation,ObjcAllocator<ObjcAssociation> > elements; { AssociationsManager manager; AssociationsHashMap &associations(manager.associations()); if (associations.size() == 0) return; disguised_ptr_t disguised_object = DISGUISE(object); AssociationsHashMap::iterator i = associations.find(disguised_object); if (i != associations.end()) { // copy all of the associations that need to be removed. ObjectAssociationMap *refs = i->second; for (ObjectAssociationMap::iterator j = refs->begin(), end = refs->end(); j != end; ++j) { elements.push_back(j->second); } // remove the secondary table. delete refs; associations.erase(i); } } // the calls to releaseValue() happen outside of the lock. for_each(elements.begin(), elements.end(), ReleaseValue()); }
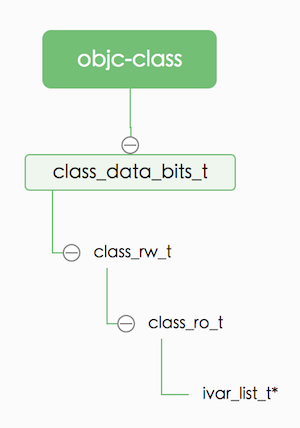
/* realizeClass * Performs first-time initialization on class cls, * including allocating its read-write data. * Returns the real class structure for the class. * Locking: runtimeLock must be write-locked by the caller */ static Class realizeClass(Class cls){ class_rw_t *rw = cls->data(); //...省略 if (ro->instanceStart < super_ro->instanceSize) { // Superclass has changed size. This class's ivars must move. // Also slide layout bits in parallel. // This code is incapable of compacting the subclass to // compensate for a superclass that shrunk, so don't do that. class_ro_t *ro_w = make_ro_writeable(rw); ro = rw->ro; moveIvars(ro_w, super_ro->instanceSize, mergeLayouts ? &ivarBitmap : nil, mergeLayouts ? &weakBitmap : nil); gdb_objc_class_changed(cls, OBJC_CLASS_IVARS_CHANGED, ro->name); layoutsChanged = YES; } // ...省略 }
/*********************************************************************** * moveIvars * Slides a class's ivars to accommodate the given superclass size. * Also slides ivar and weak GC layouts if provided. * Ivars are NOT compacted to compensate for a superclass that shrunk. * Locking: runtimeLock must be held by the caller. **********************************************************************/ staticvoidmoveIvars(class_ro_t *ro, uint32_t superSize, layout_bitmap *ivarBitmap, layout_bitmap *weakBitmap) { rwlock_assert_writing(&runtimeLock);
if (ro->ivars) { // Find maximum alignment in this class's ivars uint32_t maxAlignment = 1; for (i = 0; i < ro->ivars->count; i++) { ivar_t *ivar = ivar_list_nth(ro->ivars, i); if (!ivar->offset) continue; // anonymous bitfield
// Compute a slide value that preserves that alignment uint32_t alignMask = maxAlignment - 1; if (diff & alignMask) diff = (diff + alignMask) & ~alignMask;
// Slide all of this class's ivars en masse for (i = 0; i < ro->ivars->count; i++) { ivar_t *ivar = ivar_list_nth(ro->ivars, i); if (!ivar->offset) continue; // anonymous bitfield
if (!ro->ivars) { // No ivars slid, but superclass changed size. // Expand bitmap in preparation for layout_bitmap_splat(). if (ivarBitmap) layout_bitmap_grow(ivarBitmap, ro->instanceSize >> WORD_SHIFT); if (weakBitmap) layout_bitmap_grow(weakBitmap, ro->instanceSize >> WORD_SHIFT); } }
his function may only be called after objc_allocateClassPair and before objc_registerClassPair. Adding an instance variable to an existing class is not supported. The class must not be a metaclass. Adding an instance variable to a metaclass is not supported.
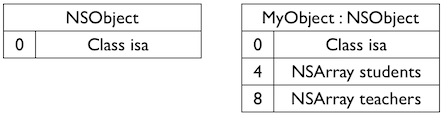
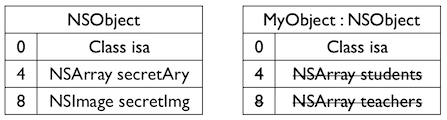
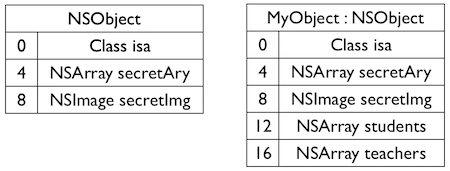
@interfaceSon : Father @property (nonatomic, copy) NSArray *toys; @end
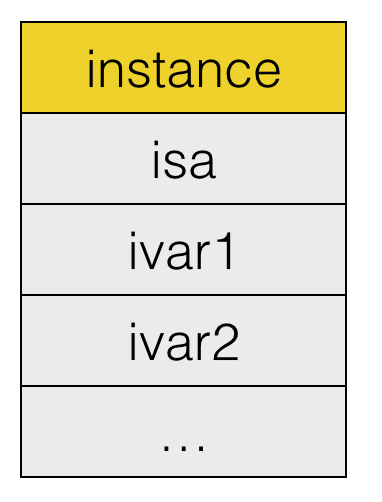
当Father初始化之后,instanceStart,instanceSize,offset已经确定。 为 Father 添加新的成员变量 sex,则使用 Son 的实例对象 son 会出错误,因为 son.instanceStart < Father.instanceSize,即 father 成员变量的 sex 的内存区域会跟 son 的一部分重合
A class may provide a method definition for an instance method named dealloc. This method will be called after the final release of the object but before it is deallocated or any of its instance variables are destroyed. The superclass’s implementation of dealloc will be called automatically when the method returns.
The instance variables for an ARC-compiled class will be destroyed at some point after control enters the dealloc method for the root class of the class. The ordering of the destruction of instance variables is unspecified, both within a single class and between subclasses and superclasses.
void *objc_destructInstance(id obj) { if (obj) { // Read all of the flags at once for performance. bool cxx = obj->hasCxxDtor(); bool assoc = !UseGC && obj->hasAssociatedObjects(); bool dealloc = !UseGC;
// This order is important. if (cxx) object_cxxDestruct(obj); if (assoc) _object_remove_assocations(obj); if (dealloc) obj->clearDeallocating(); }
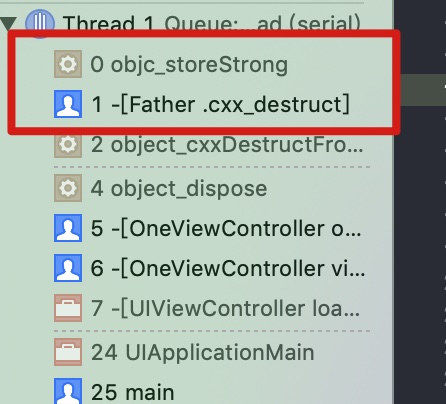
ARC actually creates a -.cxx_destruct method to handle freeing instance variables. This method was originally created for calling C++ destructors automatically when an object was destroyed.
和《Effective Objective-C 2.0》中的:
When the compiler saw that an object contained C++ objects, it would generate a method called .cxx_destruct. ARC piggybacks on this method and emits the required cleanup code within it.
可以了解到cxx_destruct方法原本是为了 C++ 对象析构的,ARC 借用了这个方法插入代码实现了自动释放的工作。
const ObjCInterfaceDecl *iface = impl->getClassInterface(); for (const ObjCIvarDecl *ivar = iface->all_declared_ivar_begin(); ivar; ivar = ivar->getNextIvar()) { QualType type = ivar->getType();
// Check whether the ivar is a destructible type. QualType::DestructionKind dtorKind = type.isDestructedType(); if (!dtorKind) continue;
CodeGenFunction::Destroyer *destroyer = 0;
// Use a call to objc_storeStrong to destroy strong ivars, for the // general benefit of the tools. if (dtorKind == QualType::DK_objc_strong_lifetime) { destroyer = destroyARCStrongWithStore;
// Otherwise use the default for the destruction kind. } else { destroyer = CGF.getDestroyer(dtorKind); }