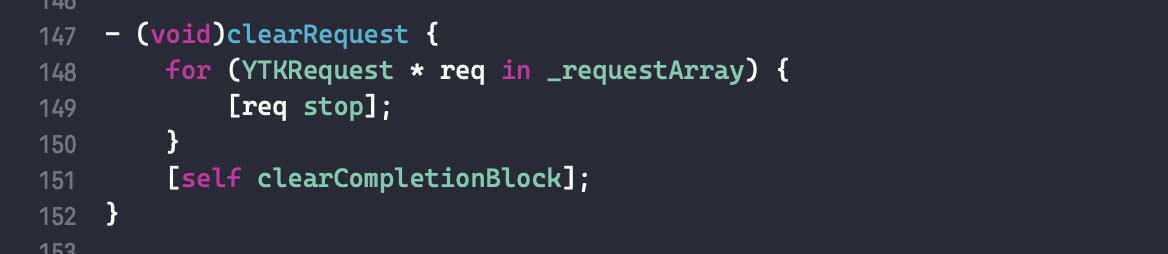
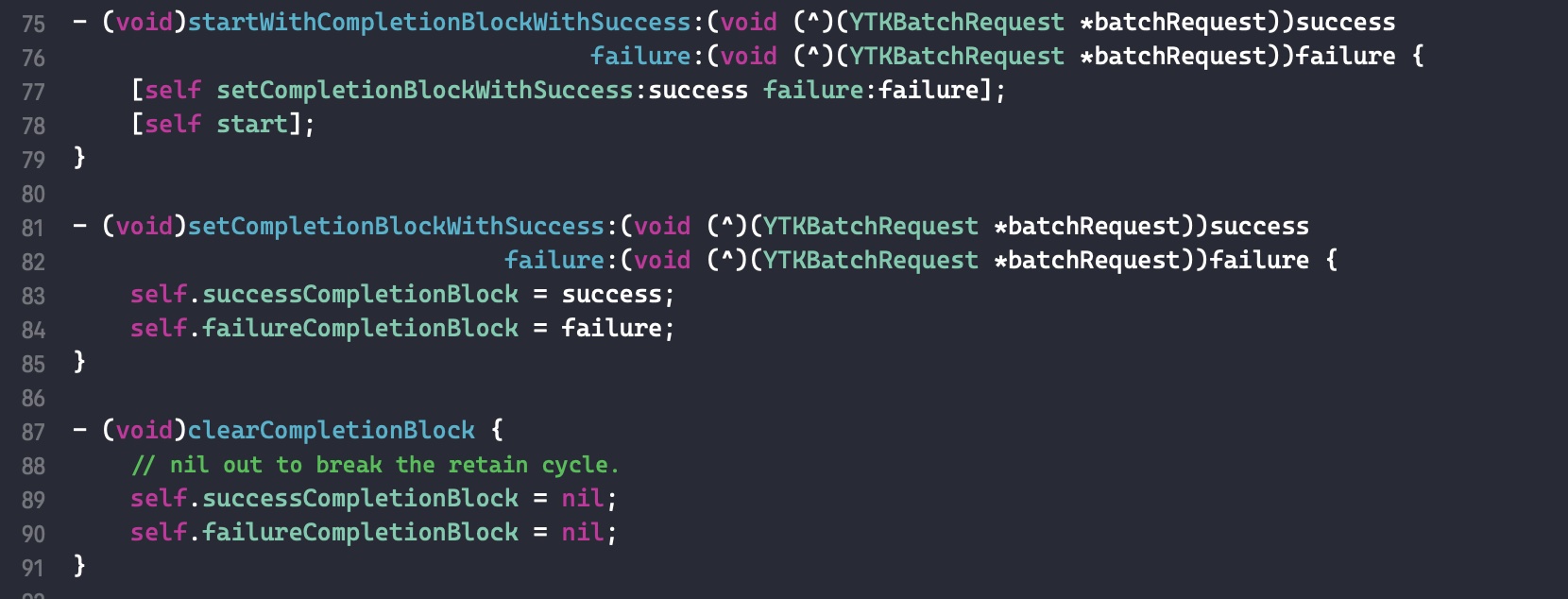
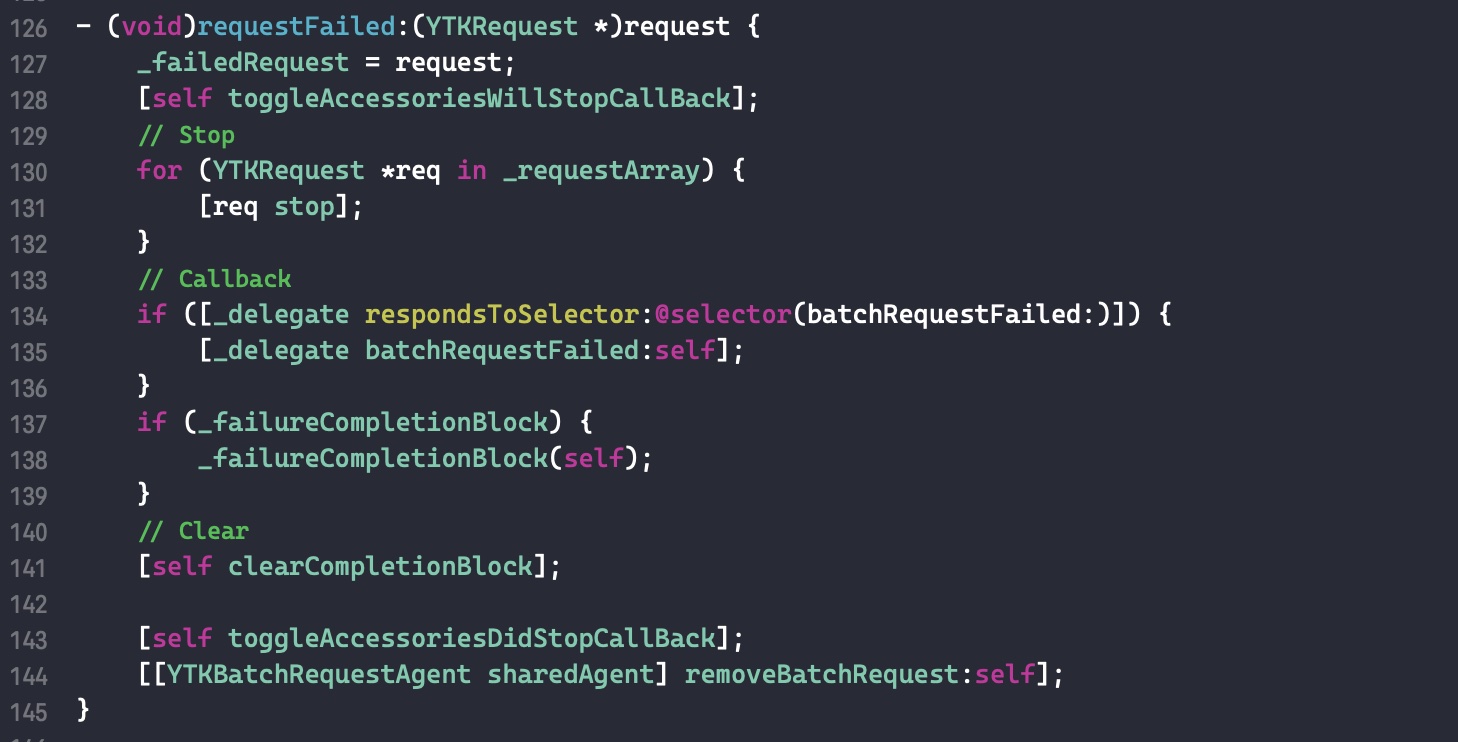
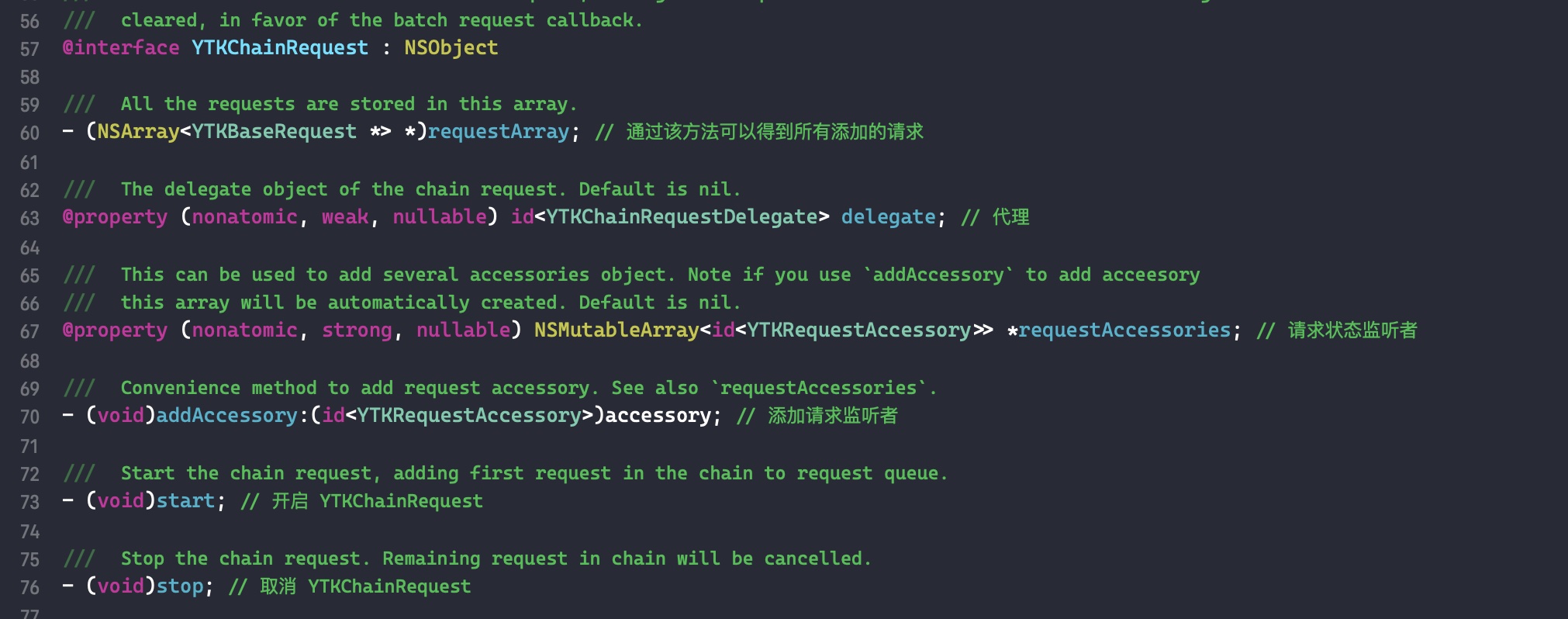
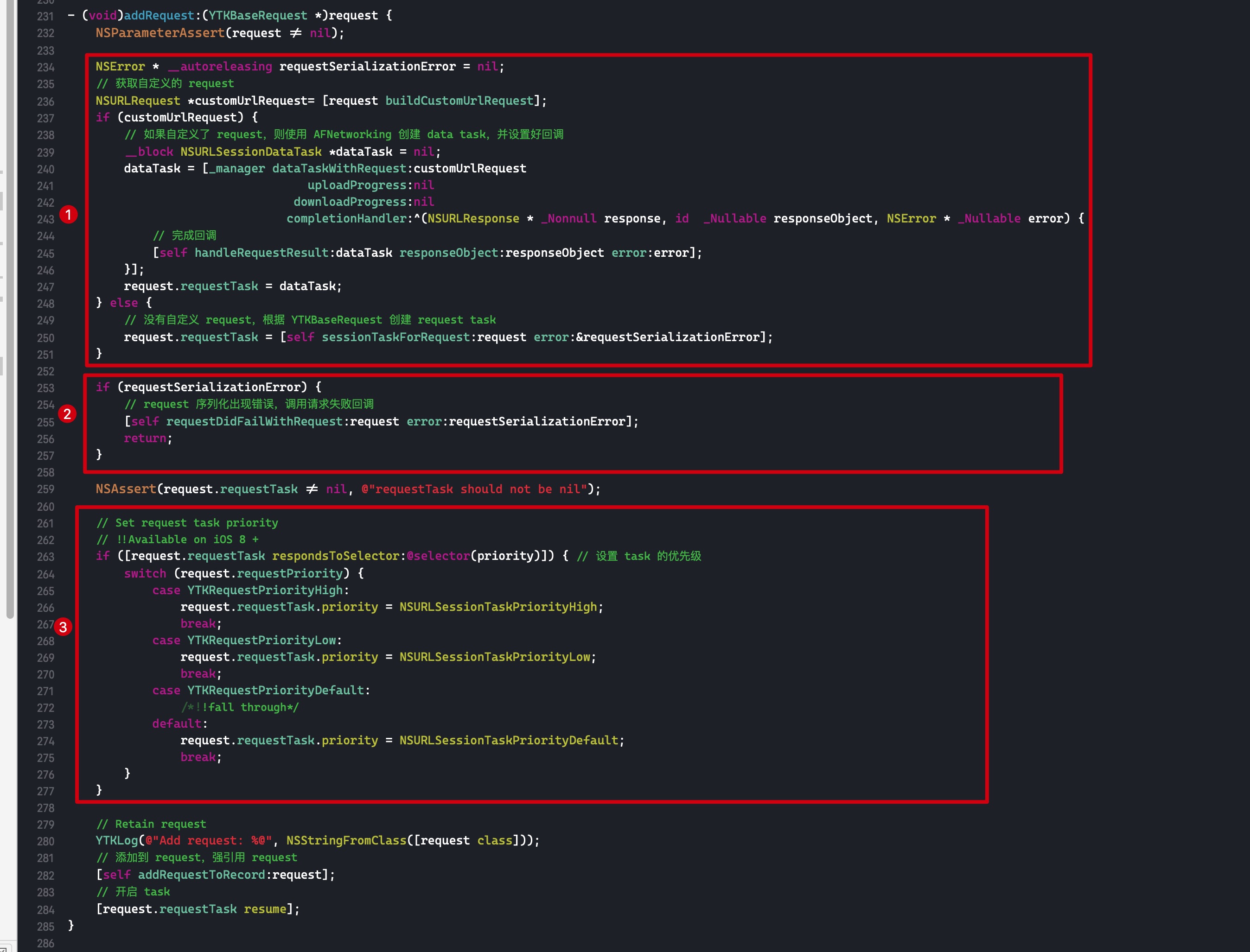
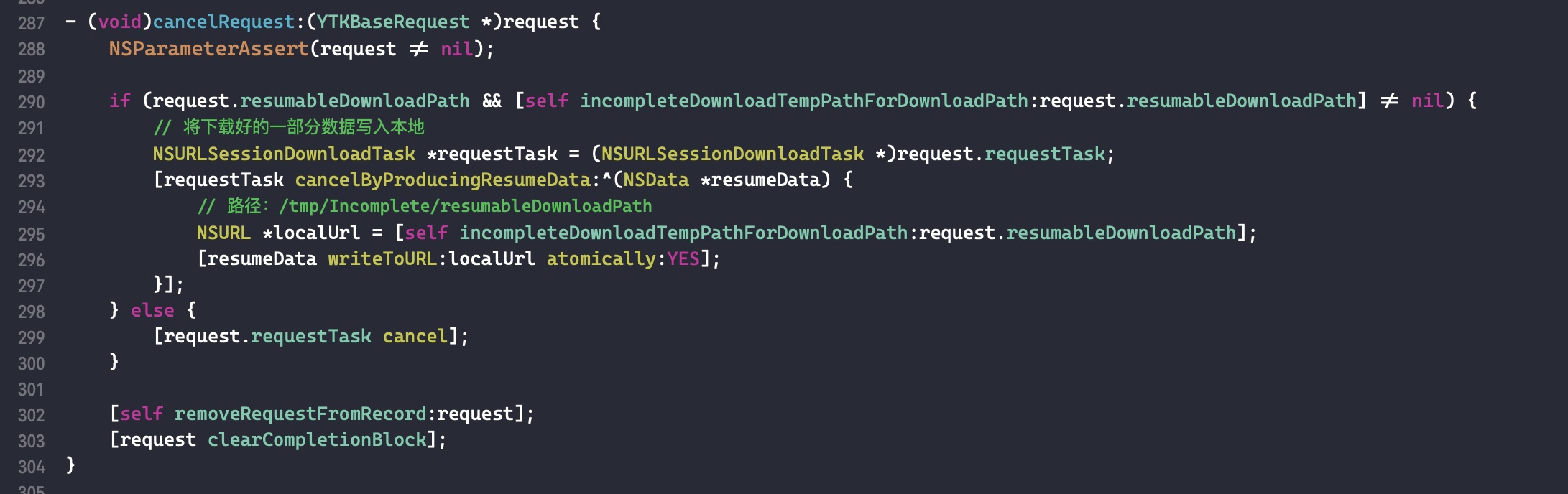
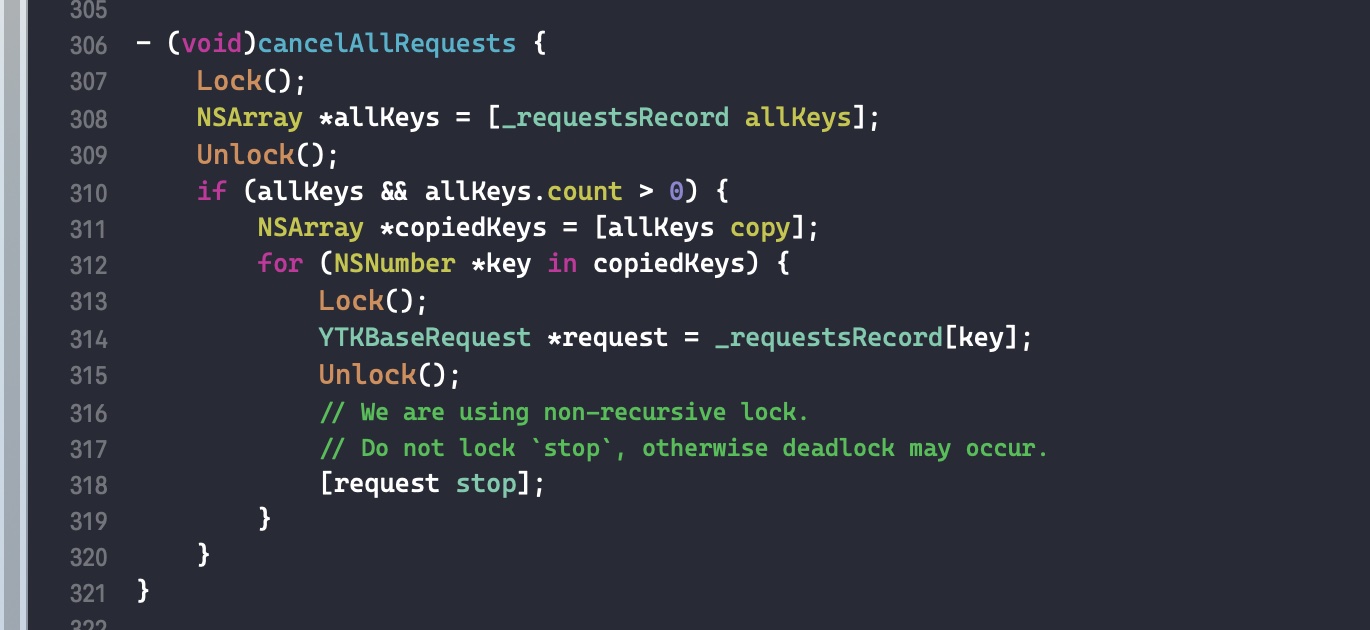
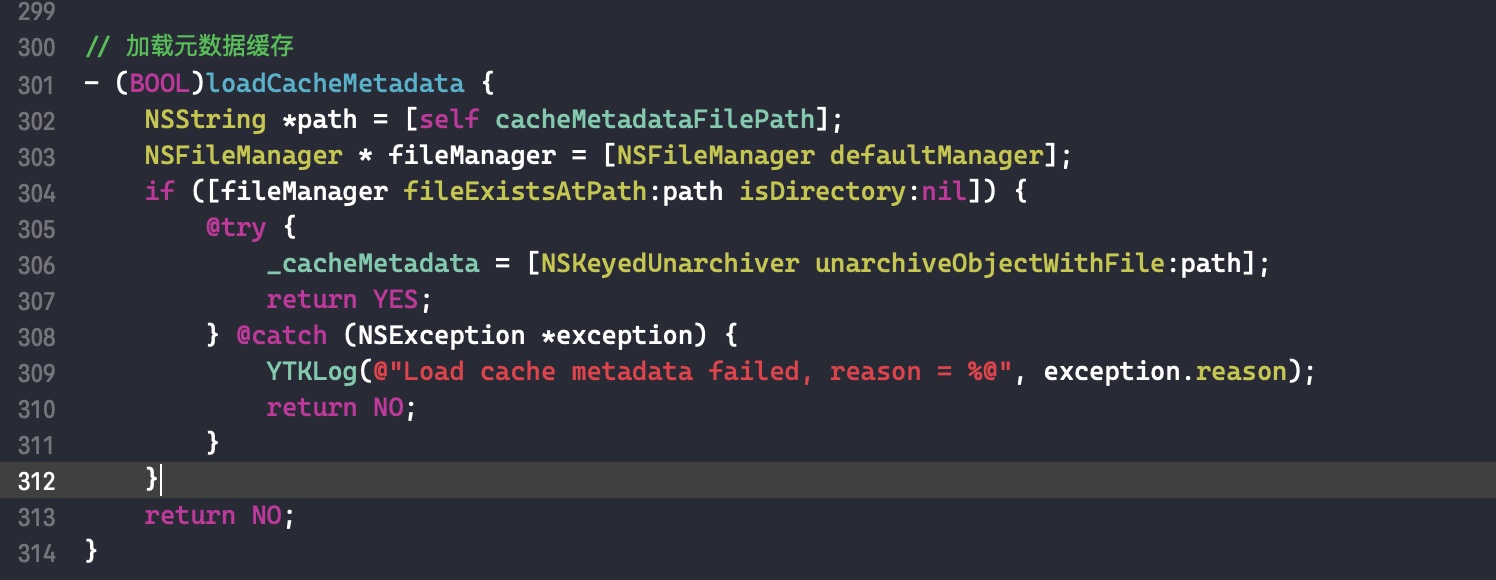
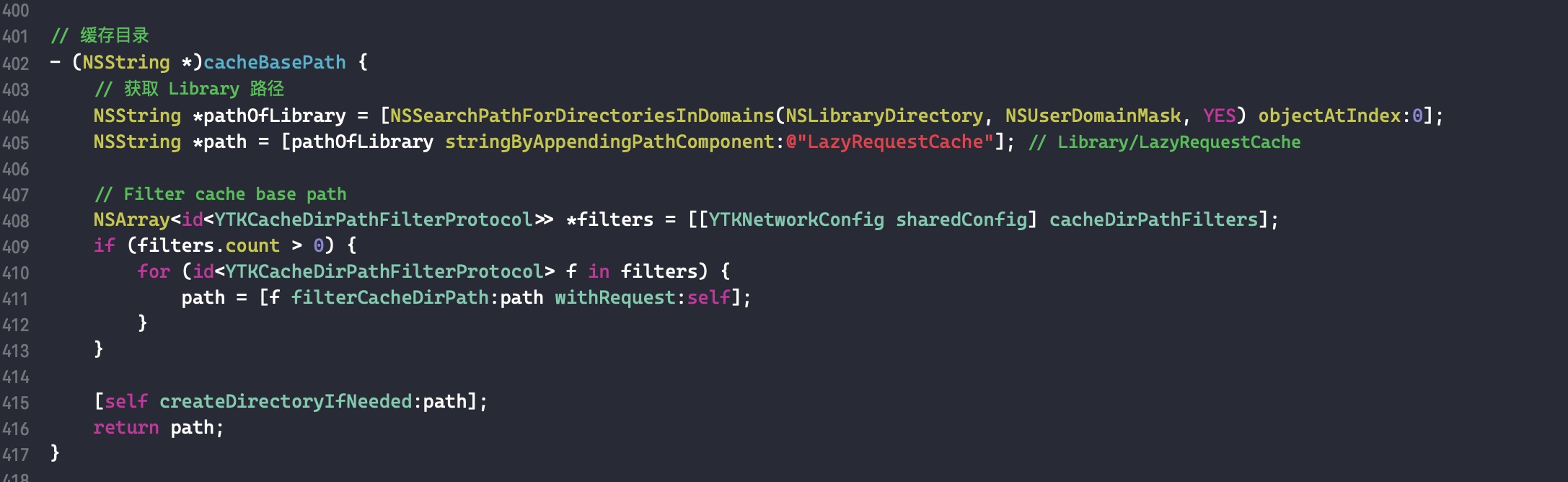
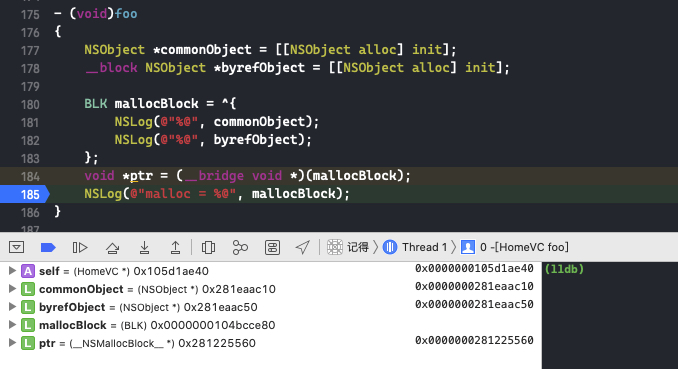
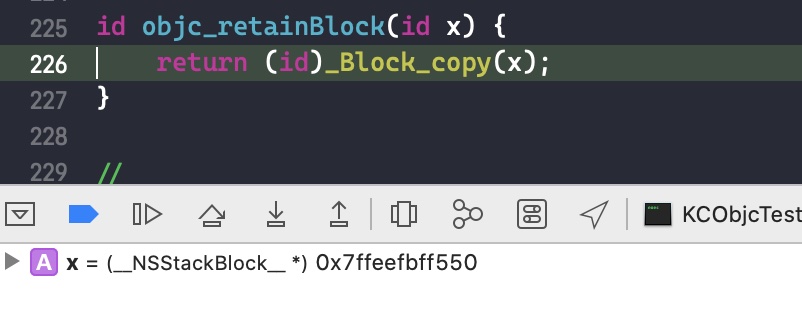
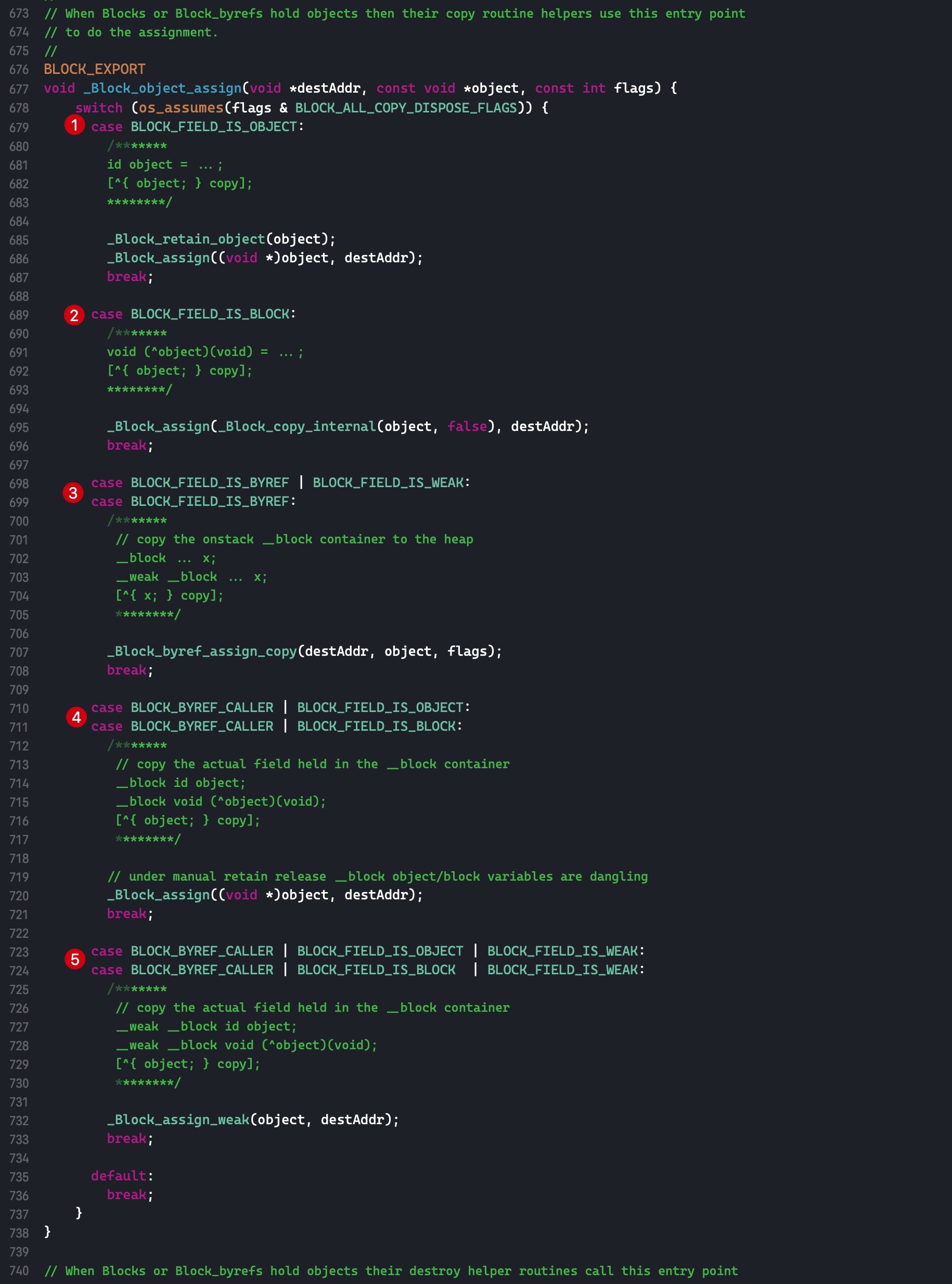
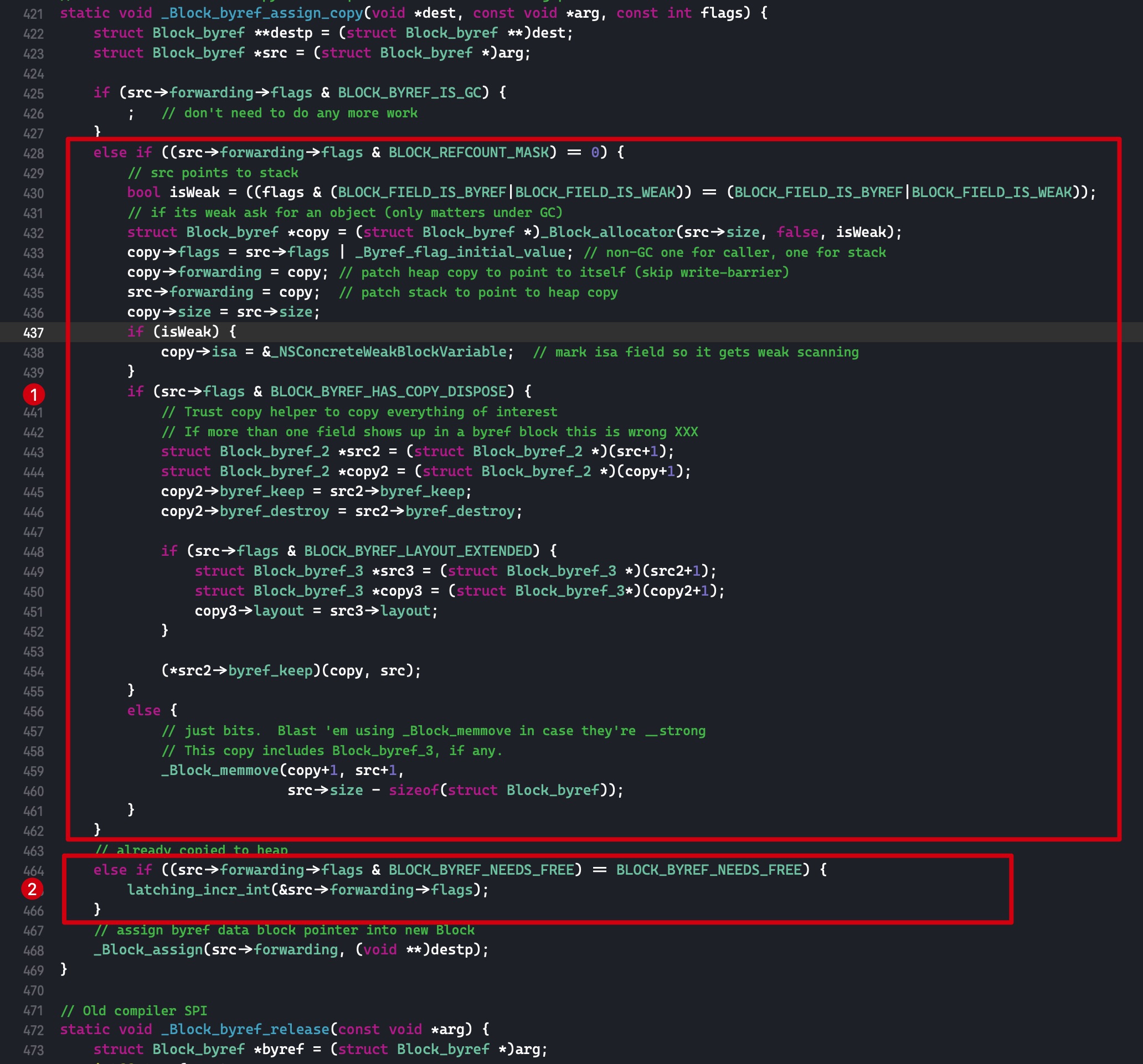
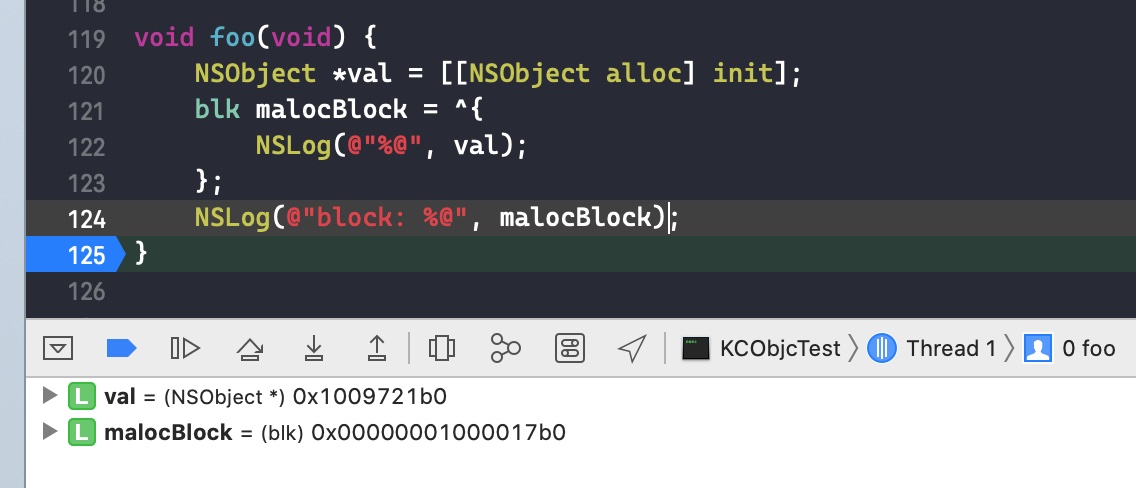
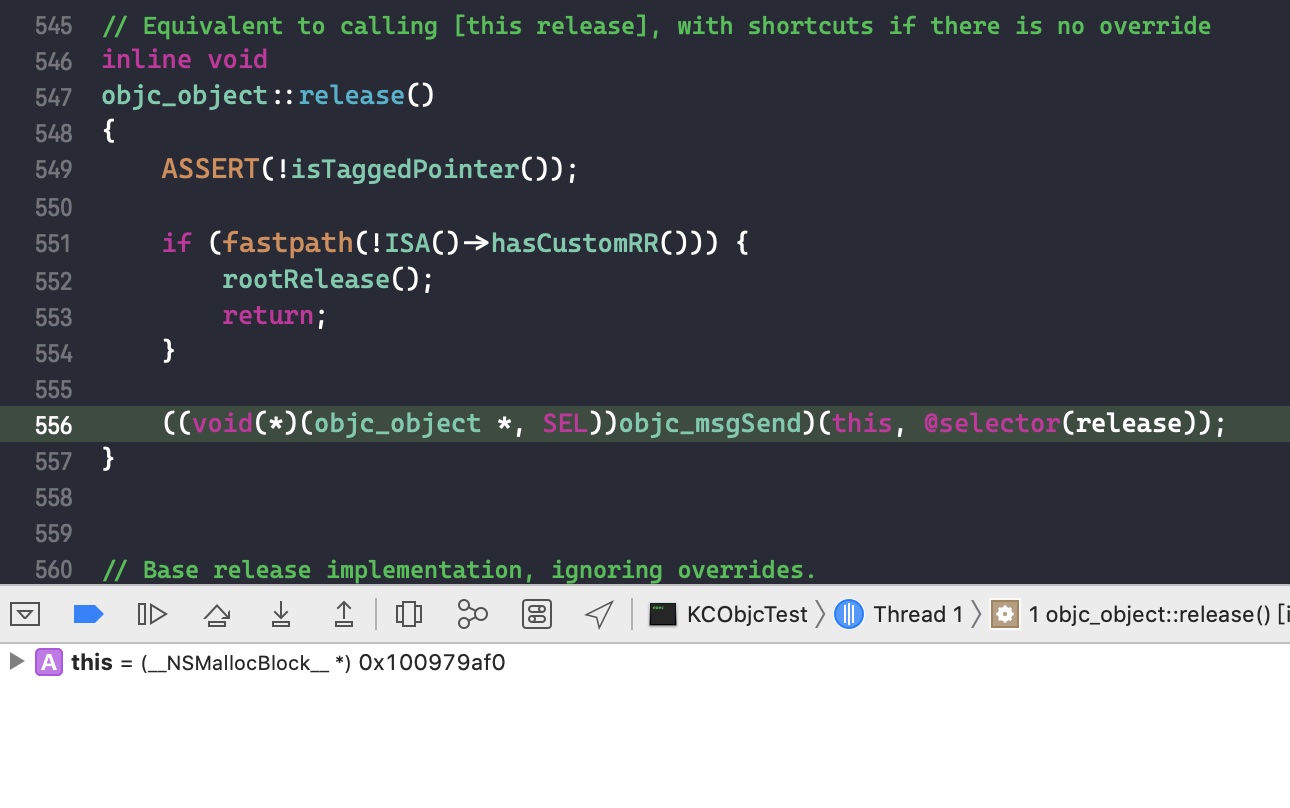
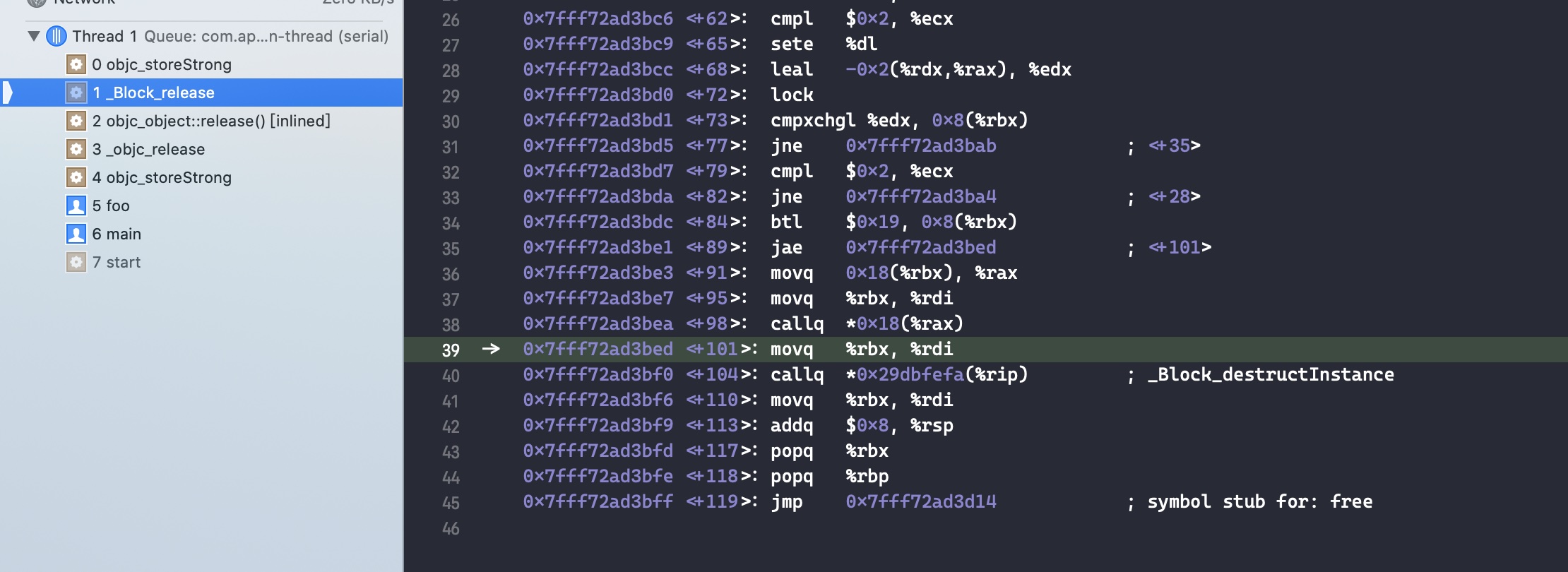
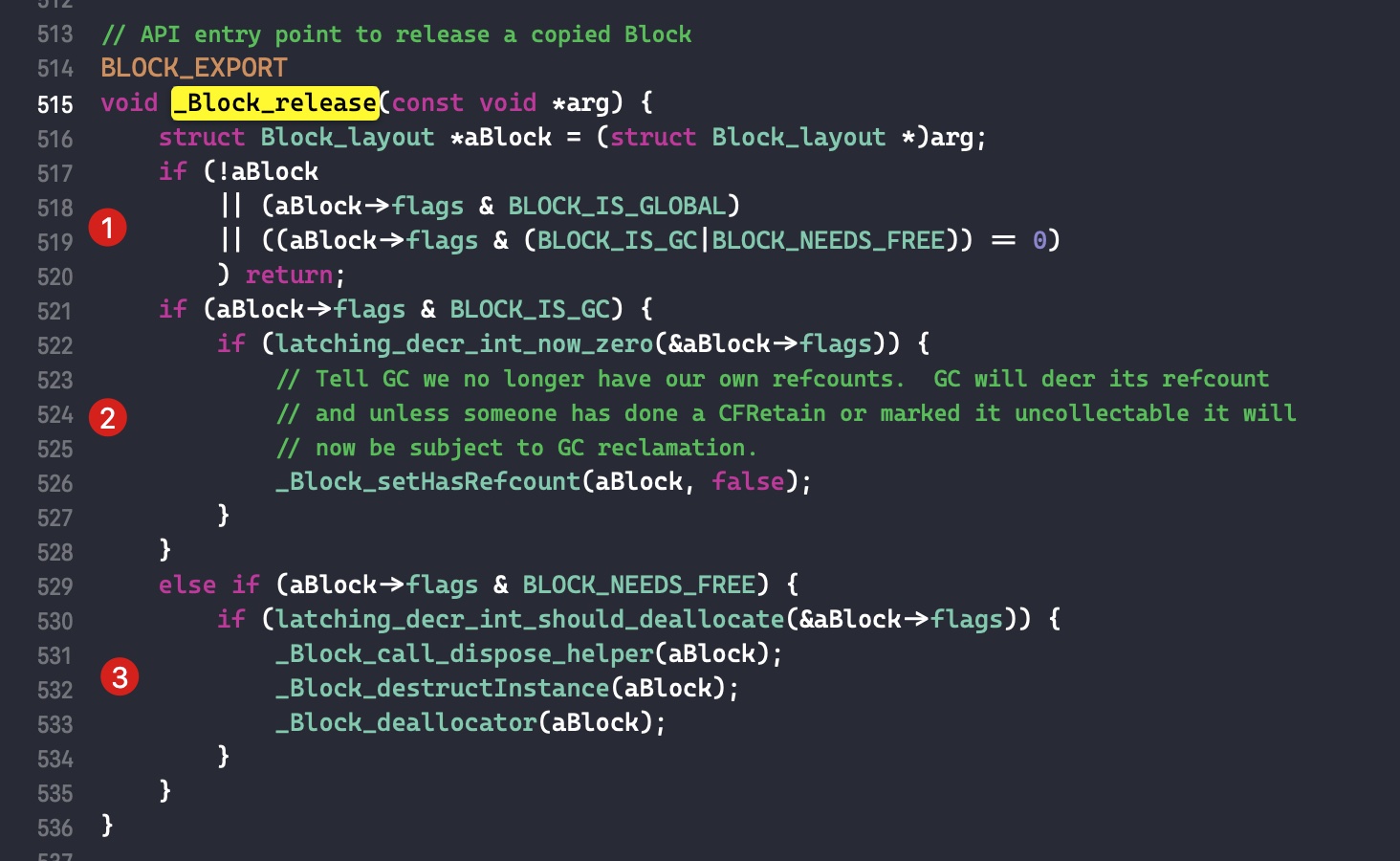
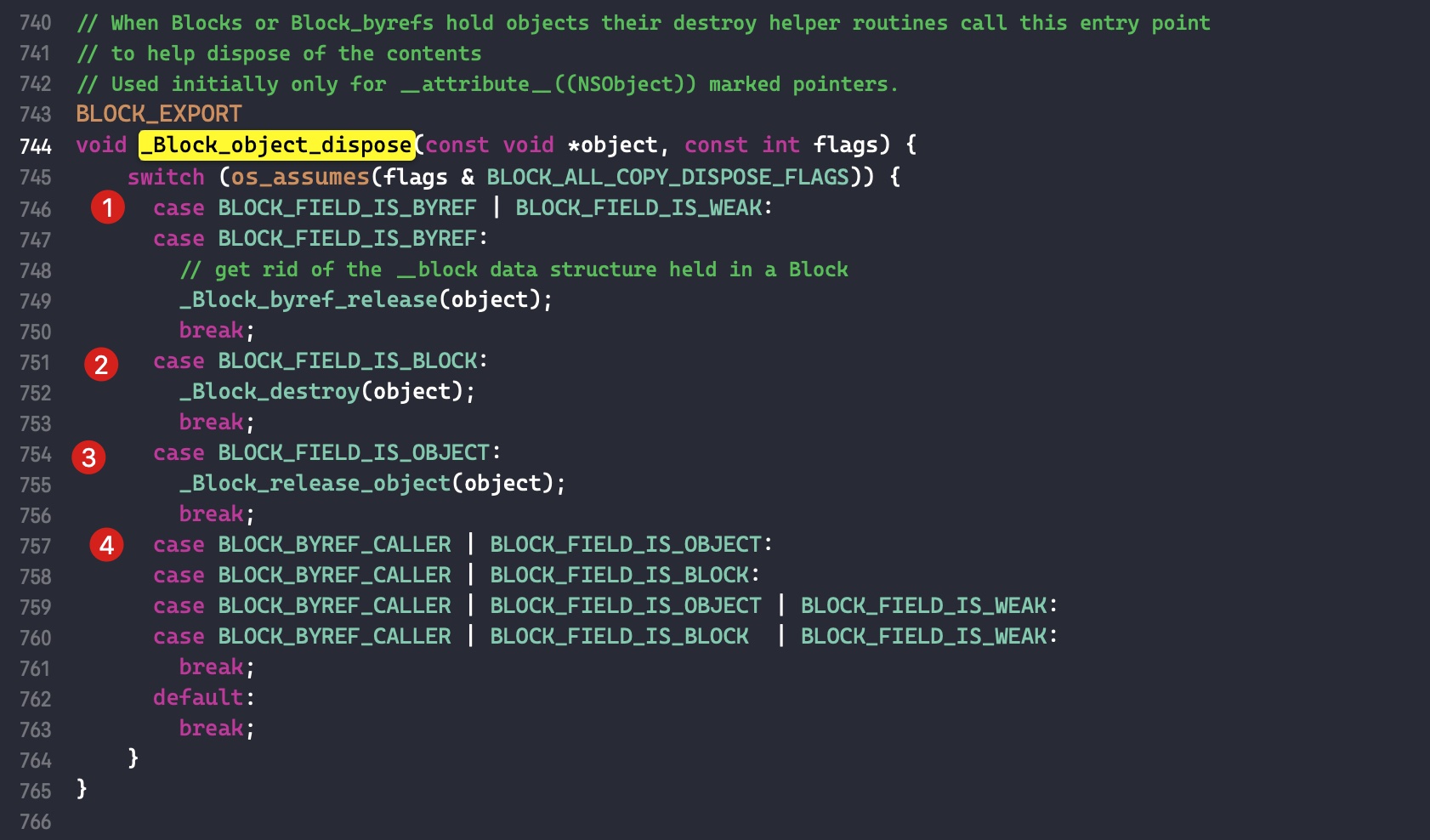
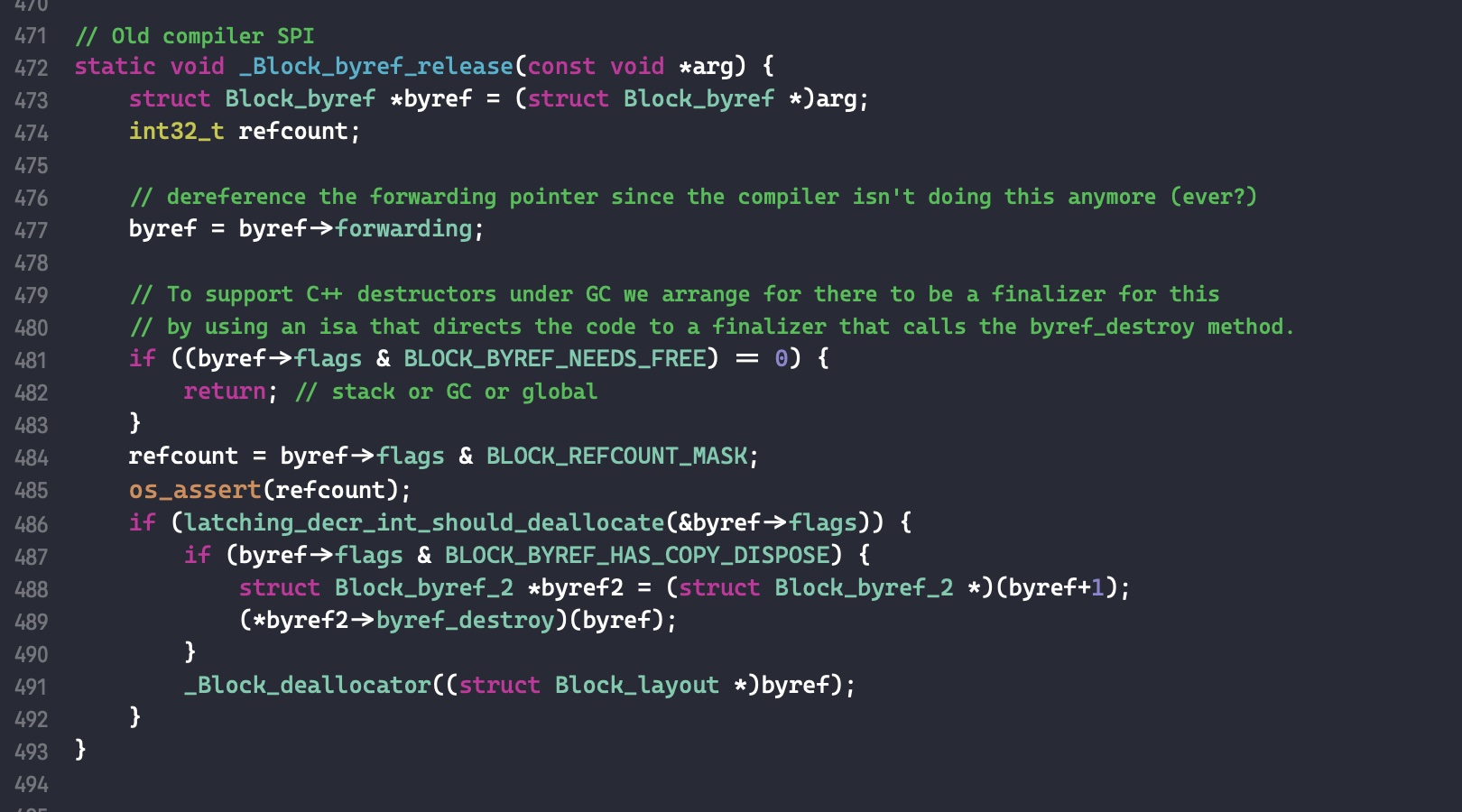
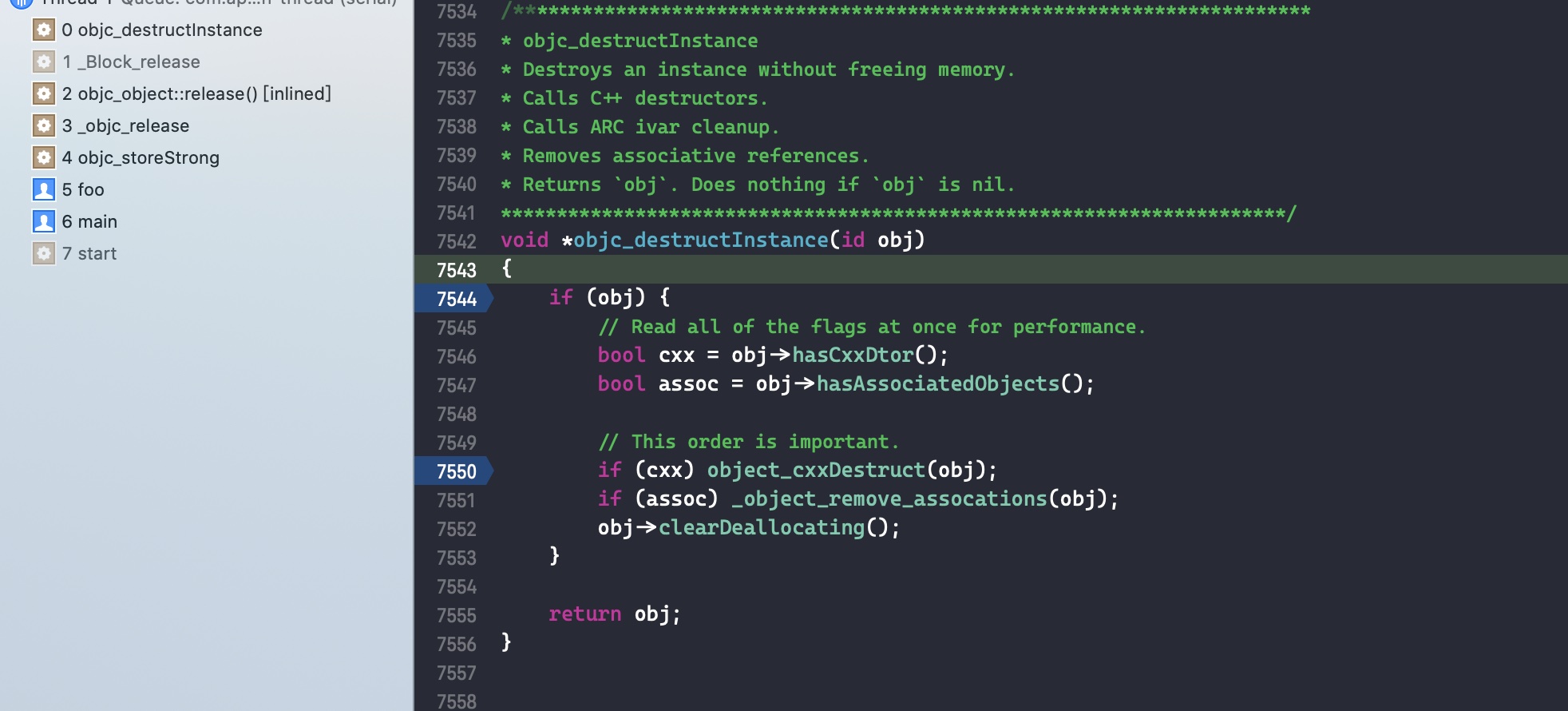
需要注意的是,如果外部变量是 C++类型,则不会调用 _Block_object_assign()函数,而是其对应的 const 拷贝构造方法。注释如下: In these cases helper functions are synthesized by the compiler for use in Block_copy and Block_release, called the copy and dispose helpers. The copy helper emits a call to the C++ const copy constructor for C++ stack based objects and for the rest calls into the runtime support function _Block_object_assign. The dispose helper has a call to the C++ destructor for case 1 and a call into _Block_object_dispose for the rest.
// FIXME: Switch to inheriting constructors when we drop support for older // clang versions. // NOTE: This default constructor is declared with '{}' rather than // '= default' to work around a separate bug in clang-3.8. This can // also go when we switch to inheriting constructors. DenseMapPair() {} }
// Lift some types from the dependent base class into this class for // simplicity of referring to them. using BaseT = DenseMapBase<DenseMap, KeyT, ValueT, ValueInfoT, KeyInfoT, BucketT>;
public: /// Create a DenseMap wth an optional \p InitialReserve that guarantee that /// this number of elements can be inserted in the map without grow() explicit DenseMap(unsigned InitialReserve = 0) { init(InitialReserve); } }
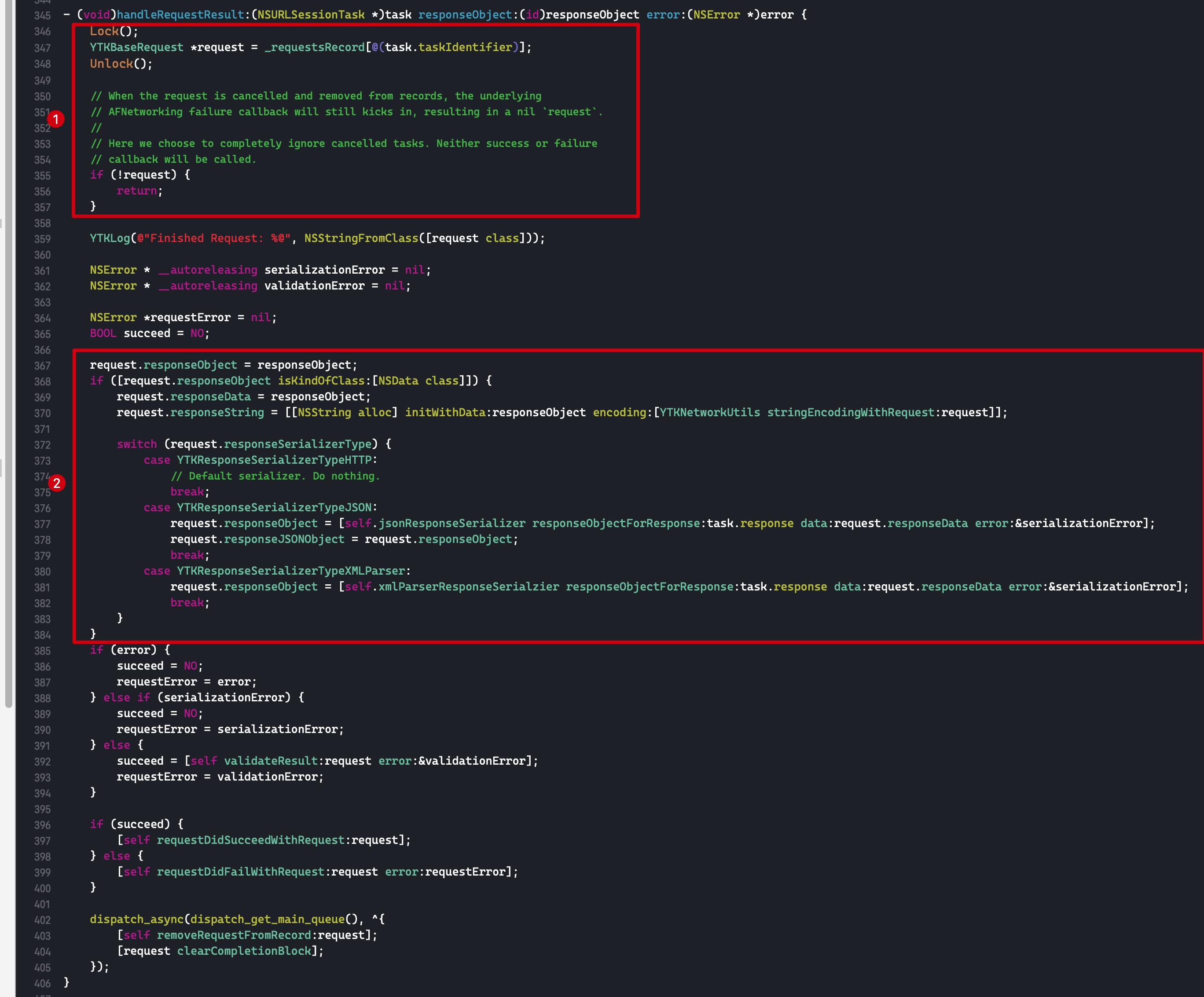
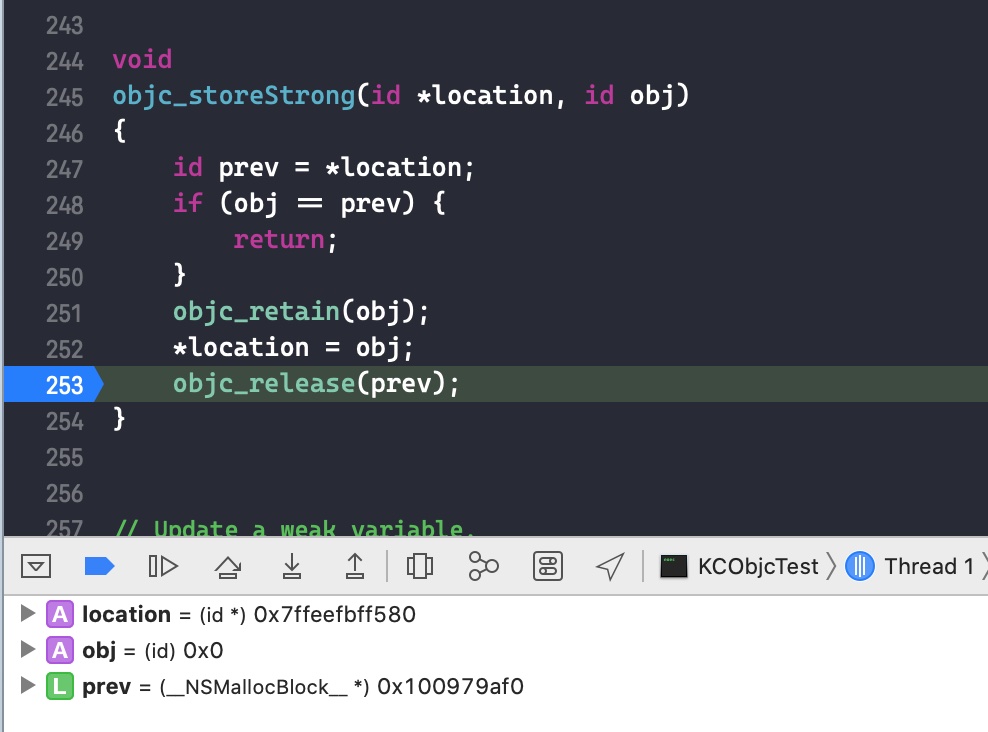
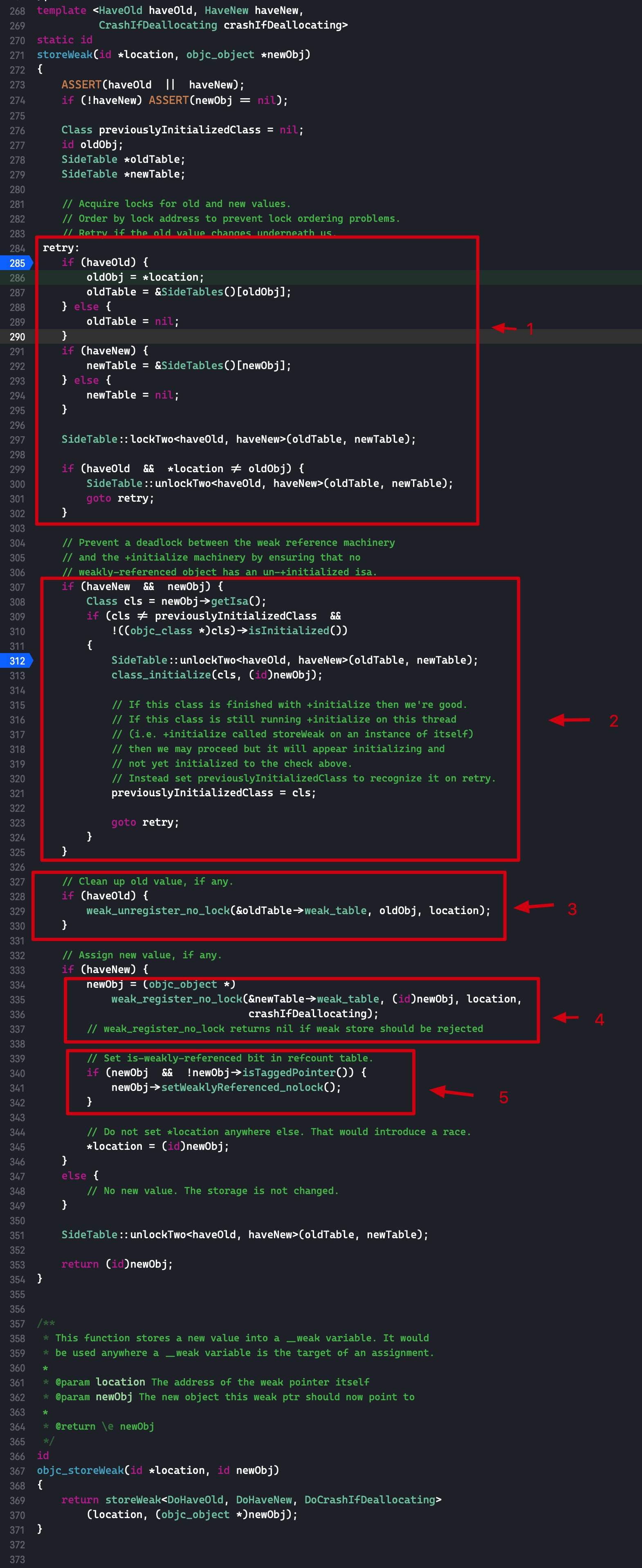
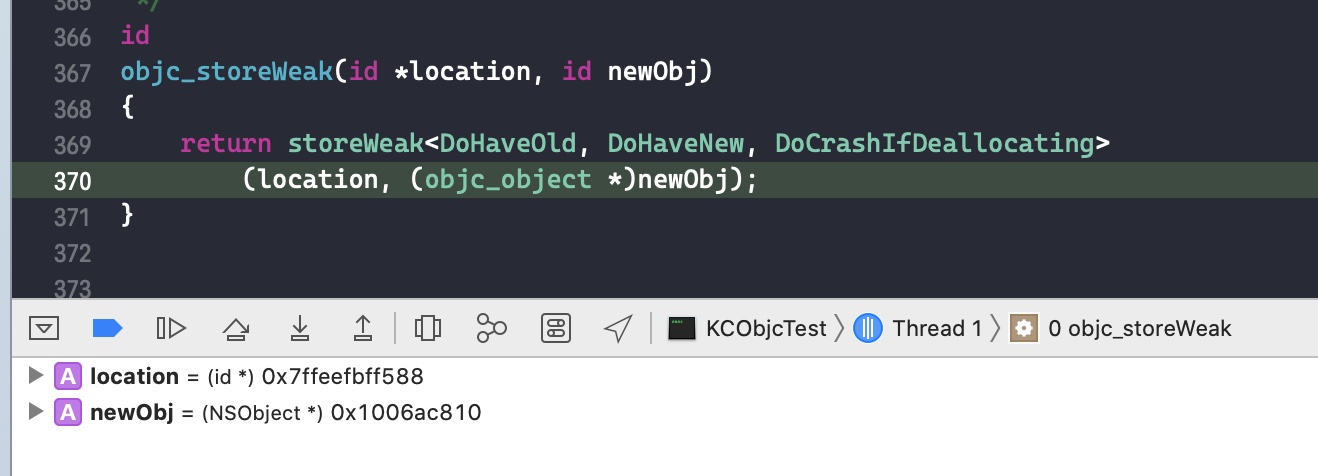
Class previouslyInitializedClass = nil; id oldObj; SideTable *oldTable; SideTable *newTable;
// Acquire locks for old and new values. // Order by lock address to prevent lock ordering problems. // Retry if the old value changes underneath us. retry: if (haveOld) { oldObj = *location; oldTable = &SideTables()[oldObj]; } else { oldTable = nil; } if (haveNew) { newTable = &SideTables()[newObj]; } else { newTable = nil; }
// Prevent a deadlock between the weak reference machinery // and the +initialize machinery by ensuring that no // weakly-referenced object has an un-+initialized isa. if (haveNew && newObj) { Class cls = newObj->getIsa(); if (cls != previouslyInitializedClass && !((objc_class *)cls)->isInitialized()) { SideTable::unlockTwo<haveOld, haveNew>(oldTable, newTable); class_initialize(cls, (id)newObj);
// If this class is finished with +initialize then we're good. // If this class is still running +initialize on this thread // (i.e. +initialize called storeWeak on an instance of itself) // then we may proceed but it will appear initializing and // not yet initialized to the check above. // Instead set previouslyInitializedClass to recognize it on retry. previouslyInitializedClass = cls;
goto retry; } }
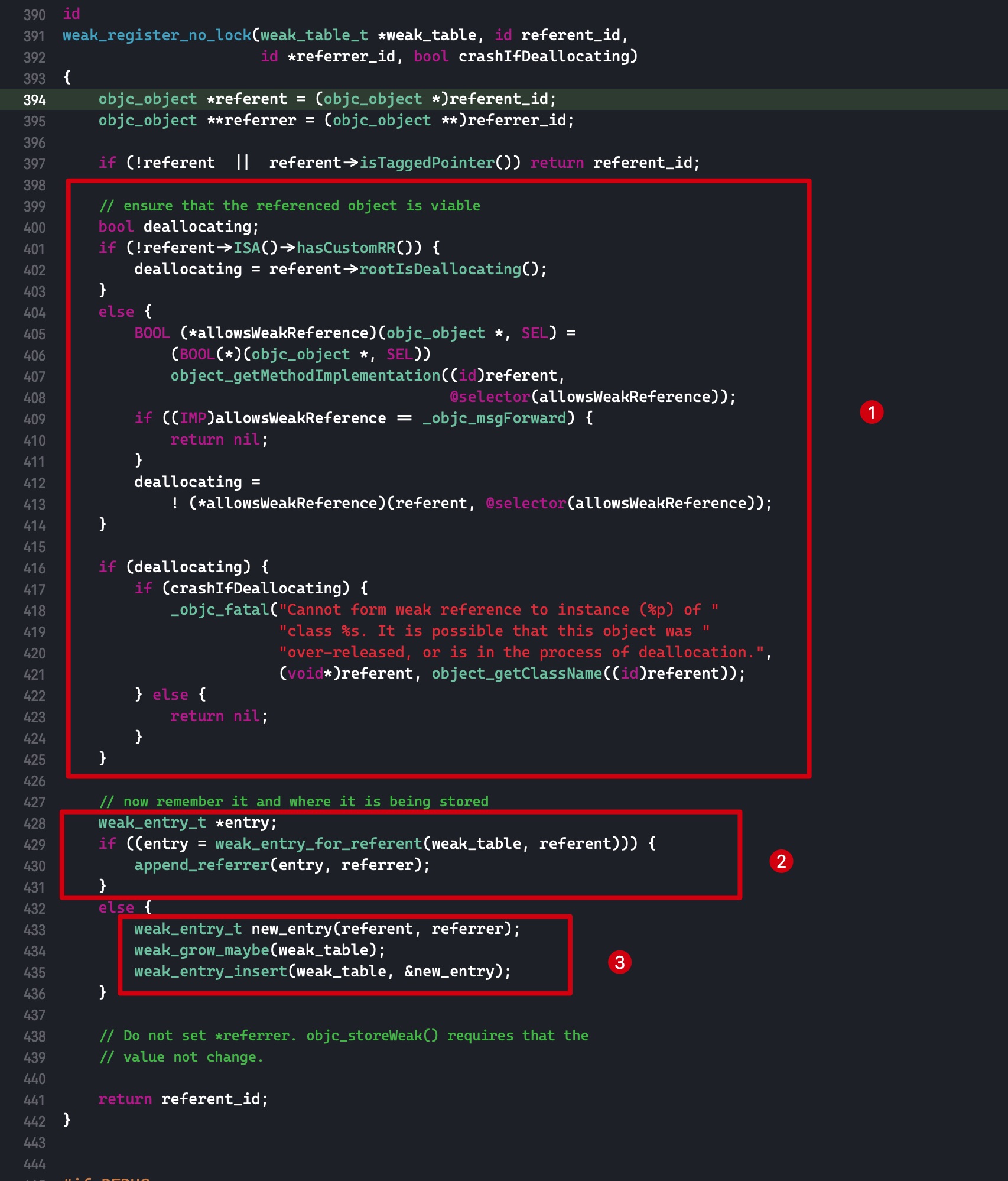
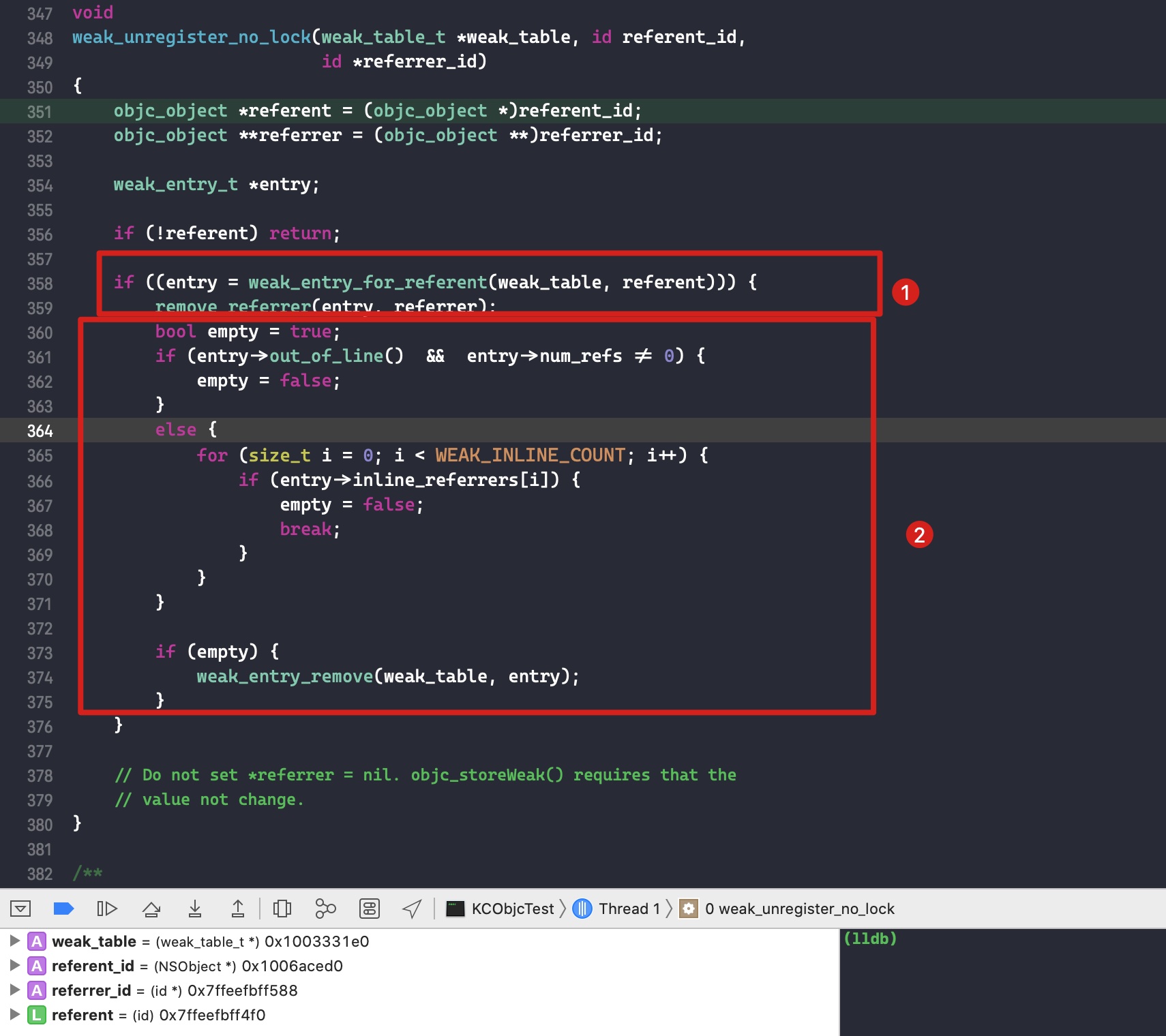
// Clean up old value, if any. if (haveOld) { weak_unregister_no_lock(&oldTable->weak_table, oldObj, location); }
// Assign new value, if any. if (haveNew) { newObj = (objc_object *) weak_register_no_lock(&newTable->weak_table, (id)newObj, location, crashIfDeallocating); // weak_register_no_lock returns nil if weak store should be rejected
// Set is-weakly-referenced bit in refcount table. if (newObj && !newObj->isTaggedPointer()) { newObj->setWeaklyReferenced_nolock(); }
// Do not set *location anywhere else. That would introduce a race. *location = (id)newObj; } else { // No new value. The storage is not changed. } SideTable::unlockTwo<haveOld, haveNew>(oldTable, newTable);
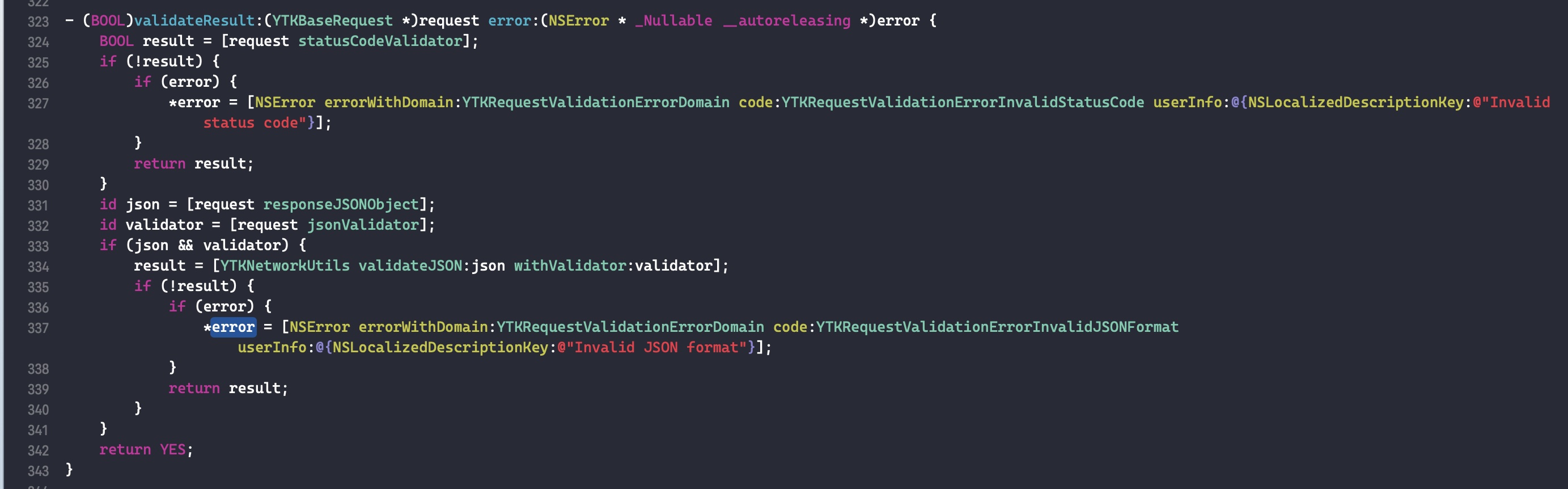
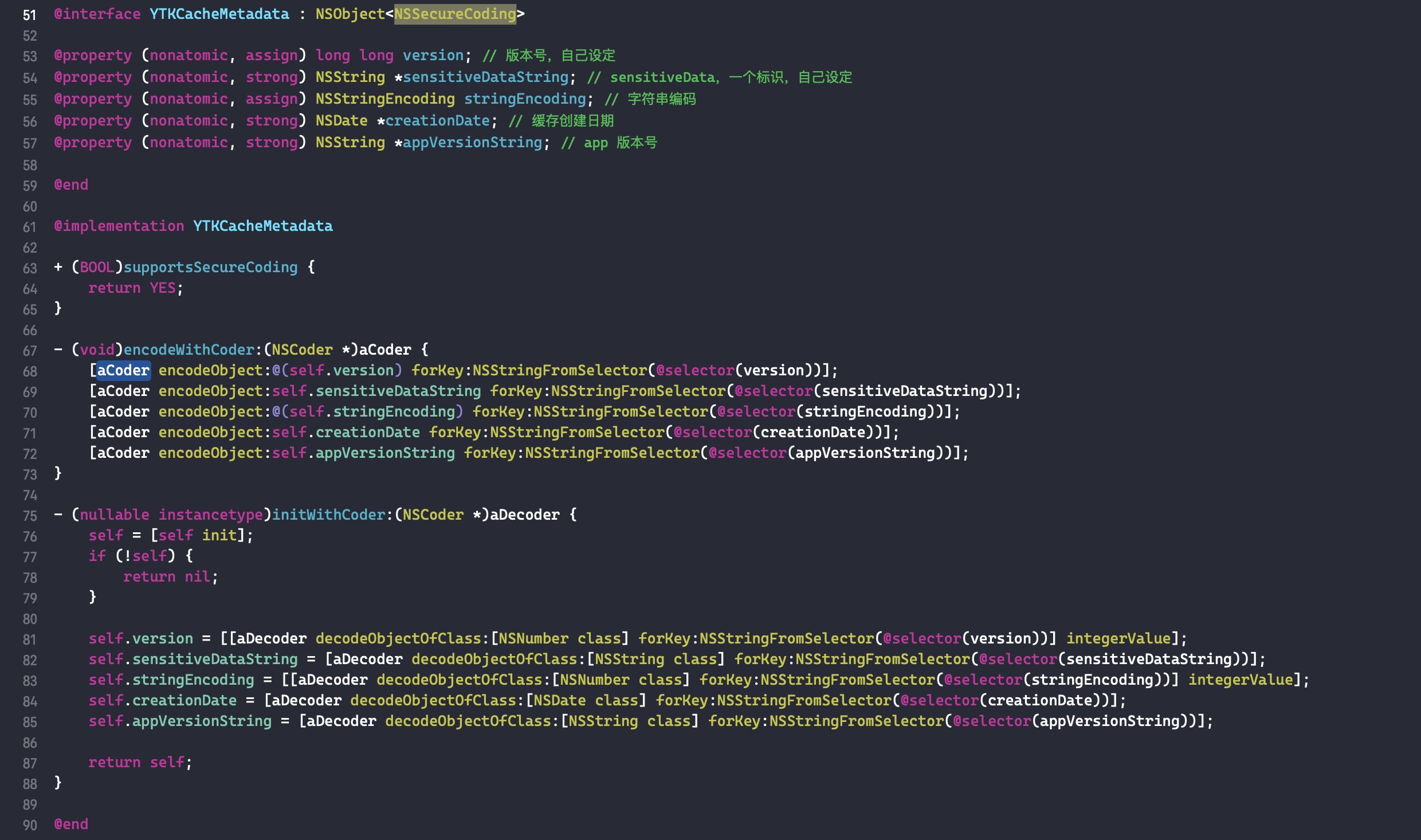
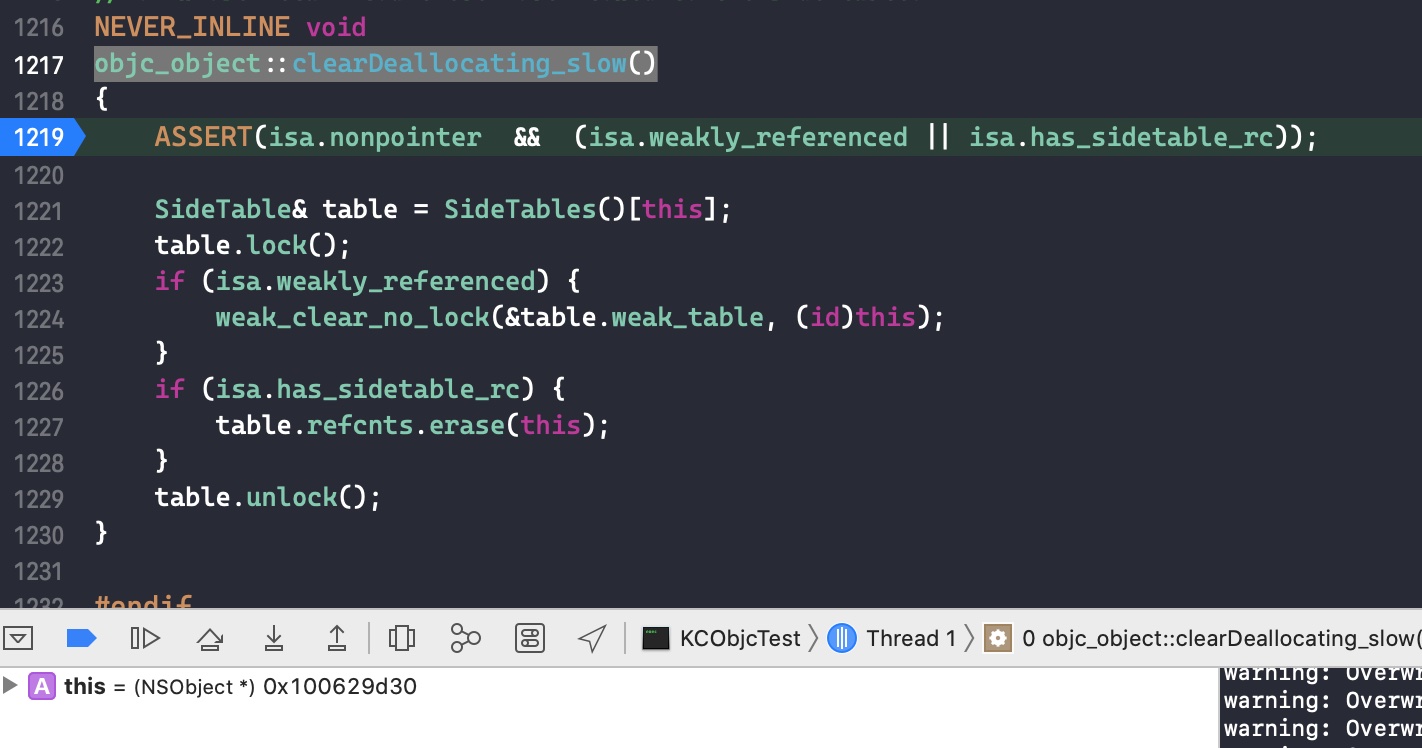
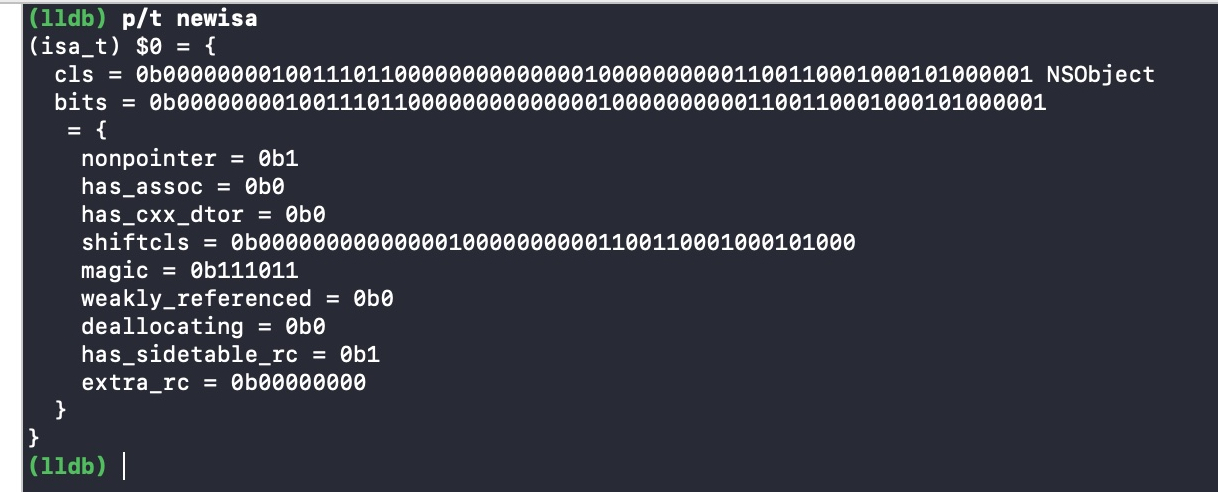
可以发现,isa_t 是一个联合体(union),几个不同类型的变量 clas 和 bits 及 struct 共用同一段内存。当 isa 指针的第一位nonpointer为 1 时表示它是优化的 isa 指针,即将多余的 bit 用来存储其它信息,从它的名字nonpointer也可以看出它不再是一个纯粹的指针了。当为 1 时,第一个成员变量cls是没有用的,因为 isa 不再使用它来指向父类 cls。下面是 isa 指针各位域的含义
变量名
含义
nonpointer
表示是否对 isa 指针开启优化 0:纯isa指针,1:存储了额外信息
has_assoc
表示该对象是否包含 associated object,如果没有,则析构时会更快
has_cxx_dtor
表示该对象是否有 C++ 或 ARC 的析构函数,如果没有,则析构时更快
shiftcls
类的指针
magic
固定值 0x1a, 用于调试器判断当前对象是真的对象还是没有初始化的空间
weakly_referenced
表示该对象是否有过 weak 对象,如果没有,则析构时更快
deallocating
表示该对象是否正在析构
has_sidetable_rc
表示该对象的引用计数值是否过大无法存储在 isa 指针
extra_rc
存储引用计数值减一后的结果
在 arm64 下, isa 使用 19 个 bit 用来存储引用计数. 当引用计数超过这个数时,将会把 RC_HALF 数量的引用计数存储在一个全局哈希表中,此时 has_sidetable_rc 变为 1
增加引用计数
下面让我们通过调试来探究具体的存储过程 因为是在模拟器中运行的,isa 最多只能使用 8 个 bit 来存储引用计数, 即在 isa 中只能存储不超过 256 的数目。所以我们只要将对象的引用计数增加到 256 以上,那么系统就会将多余的引用计数存储到哈希表。
1 2 3 4 5 6
void foo(void) { NSObject *o1 = [[NSObject alloc] init]; for (int i = 0; i < 500; i++) { _objc_rootRetain(o1); } }
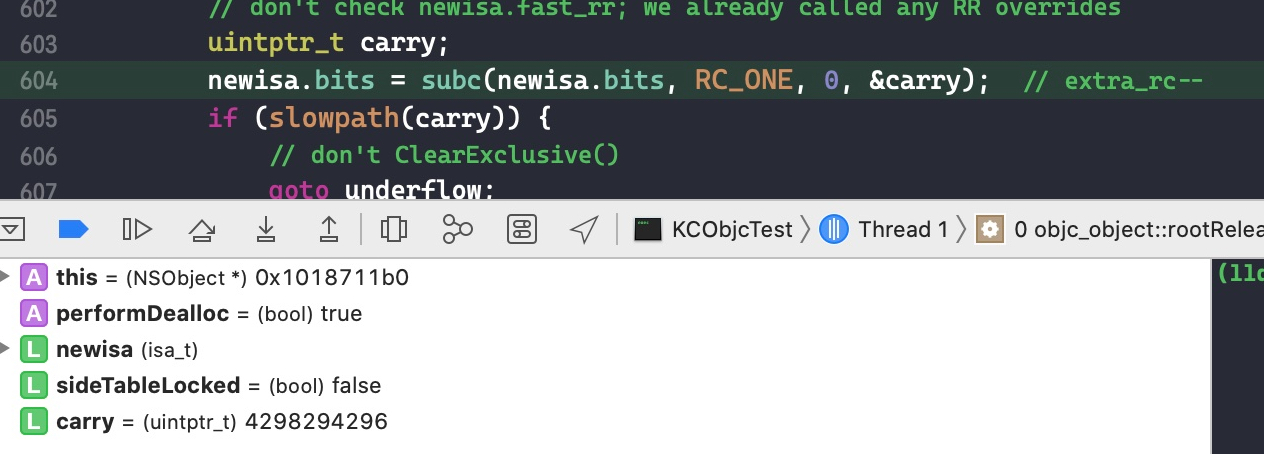
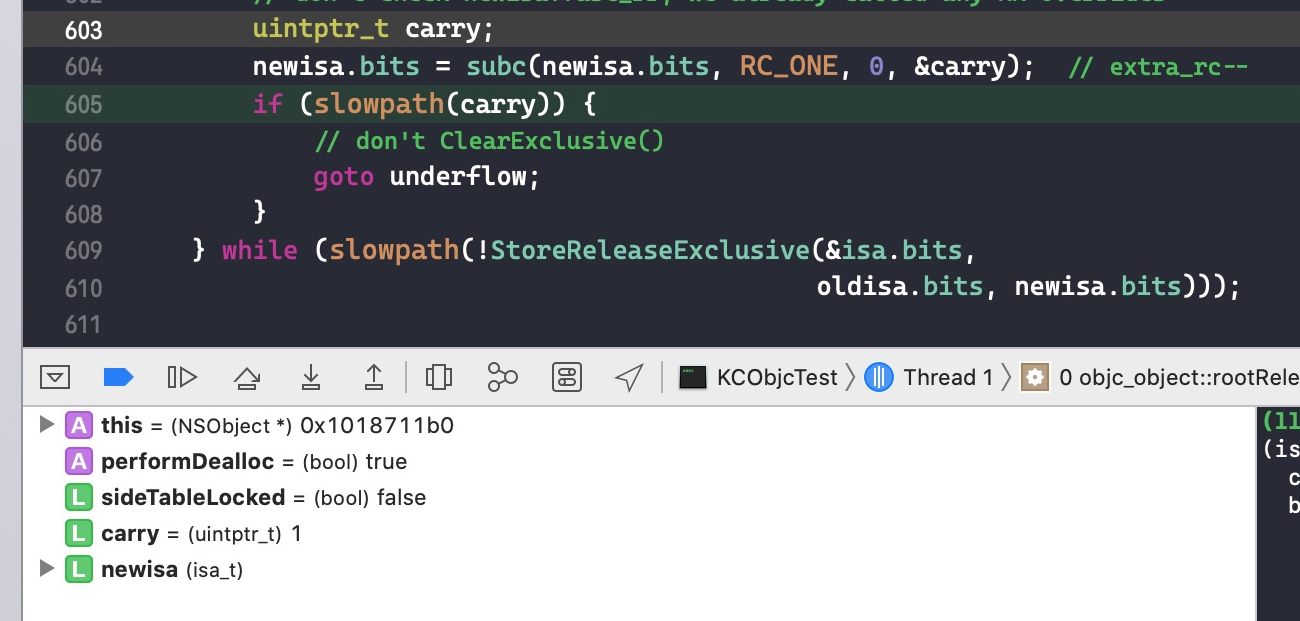
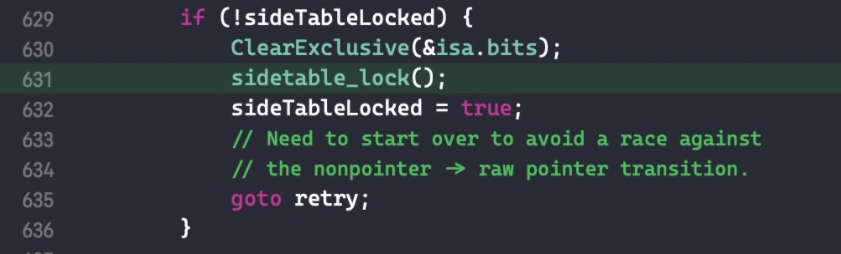
do { // 是否将引用计数转移到索引表中 transcribeToSideTable = false; // LoadExclusive 的作用是让读取操作原子化 oldisa = LoadExclusive(&isa.bits); newisa = oldisa; // if (slowpath) else (),表示大概率执行 else 后面的语句,用来提高效率。 // fastpath 则表示大概率执行 if 后面的语句 if (slowpath(!newisa.nonpointer)) { // arm64 架构下,一般的对象 nonpointer 为YES,但也有特例,例如 block 的 nonpointer 为 False,即不使用 isa 保存额外信息 ClearExclusive(&isa.bits); if (rawISA()->isMetaClass()) return (id)this; if (!tryRetain && sideTableLocked) sidetable_unlock(); if (tryRetain) return sidetable_tryRetain() ? (id)this : nil; else return sidetable_retain(); } // don't check newisa.fast_rr; we already called any RR overrides if (slowpath(tryRetain && newisa.deallocating)) { ClearExclusive(&isa.bits); if (!tryRetain && sideTableLocked) sidetable_unlock(); return nil; } // 用来表示 isa 指针的值是否溢出。因为引用计数存储在指针的高位,当引用计数增加到一定程度,会超过最高位的数字,此时 carry 的值不等于 0,表示溢出 uintptr_t carry; // addc() 是一个内置函数,作用是将 isa 里面的引用计数 + 1 后保存 newisa.bits = addc(newisa.bits, RC_ONE, 0, &carry); // extra_rc++
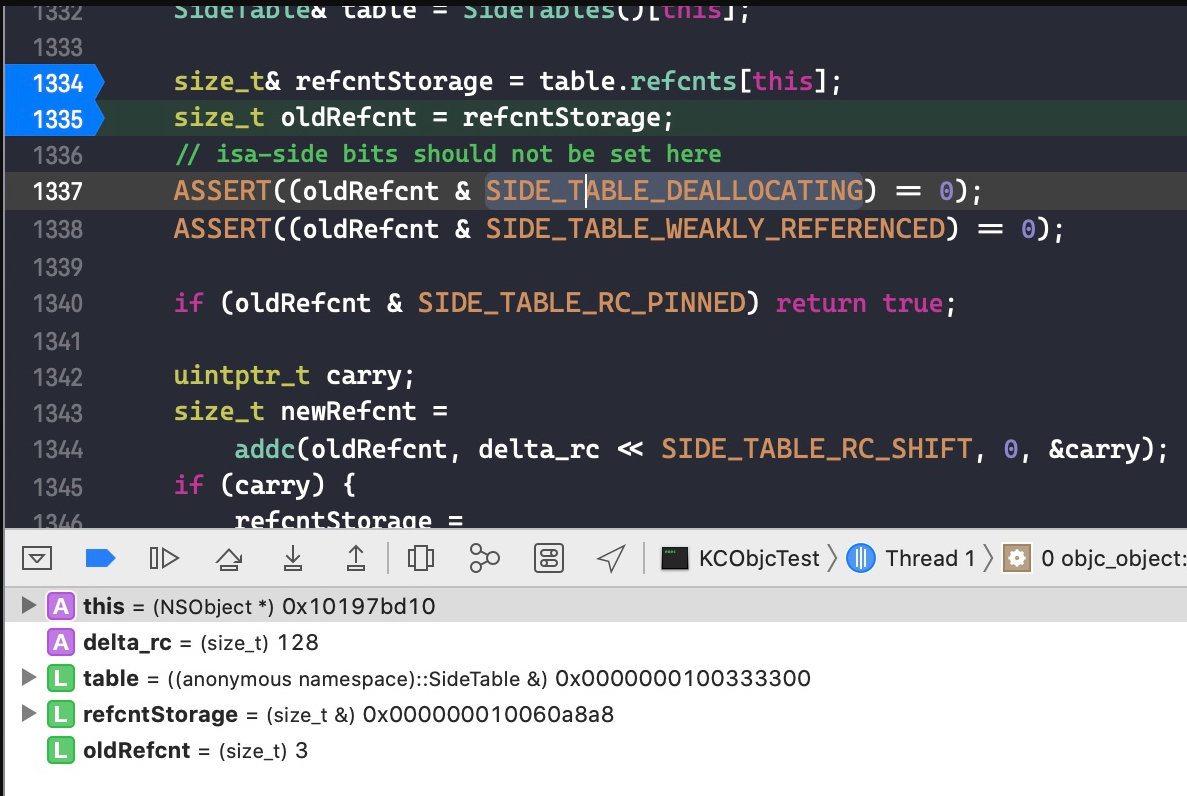
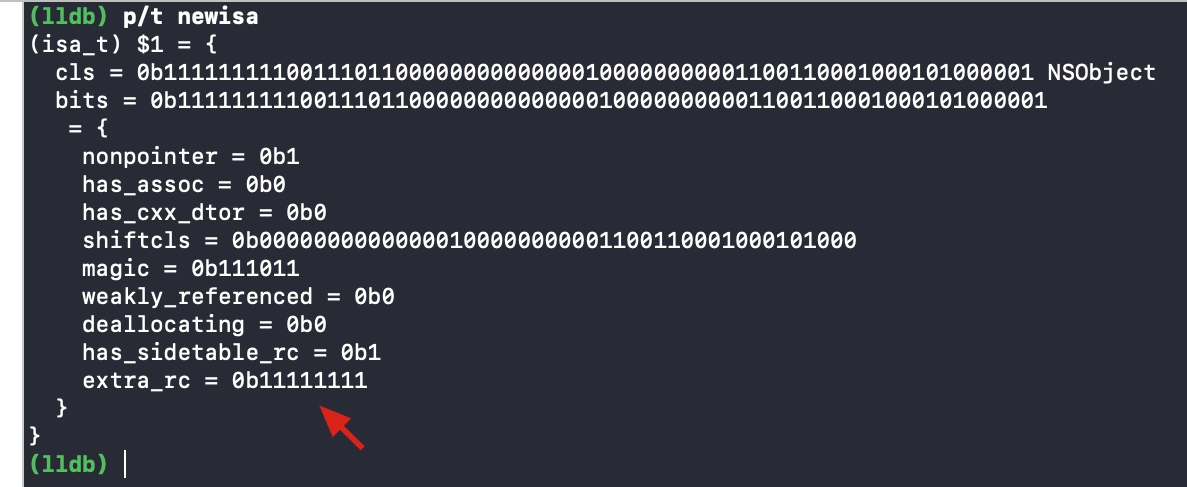
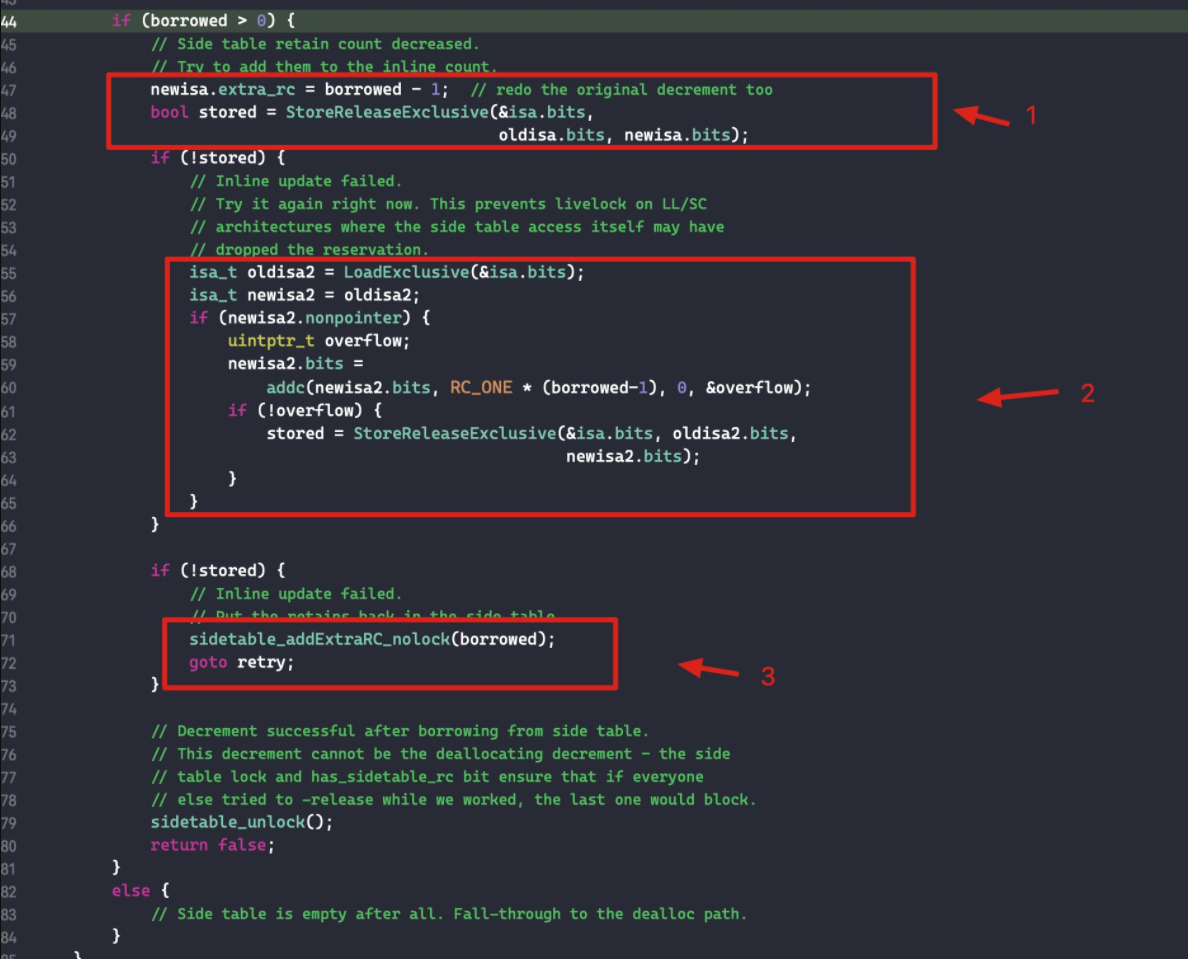
if (slowpath(carry)) { // newisa.extra_rc++ overflowed // 移除的话则需要对多余的引用计数保存到索引表中。 // 刚开始进入的时候 handleOverflow == false if (!handleOverflow) { ClearExclusive(&isa.bits); return rootRetain_overflow(tryRetain); } // 加锁 if (!tryRetain && !sideTableLocked) sidetable_lock(); // 此时 isa 指针存储的引用计数应该是满的, extra_rc 的 19 位都是 1,将 extra_rc 赋值为原来的一半,也就是将 isa 的最高位赋值为 0,这样做的目的是下次引用计数增加的时候可以直接存储在 isa 中,而不需要调用索引表来存储。将 has_sidetable_rc 赋值为 1,标记有额外的引用计数存储在索引表中 sideTableLocked = true; transcribeToSideTable = true; newisa.extra_rc = RC_HALF; newisa.has_sidetable_rc = true; } // StoreExclusive(), 如果&isa.bits和oldisa.bits相等,那么就把newisa.bits的值赋给&isa.bits,并且返回true。 } while (slowpath(!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits)));
if (slowpath(transcribeToSideTable)) { // Copy the other half of the retain counts to the side table. // 如果溢出的话,则将 isa 存储的引用计数赋值为最大值的一半,即 RC_HALF,那么减少的一半则转移到索引表中 sidetable_addExtraRC_nolock(RC_HALF); } if (slowpath(!tryRetain && sideTableLocked)) sidetable_unlock(); return (id)this; }
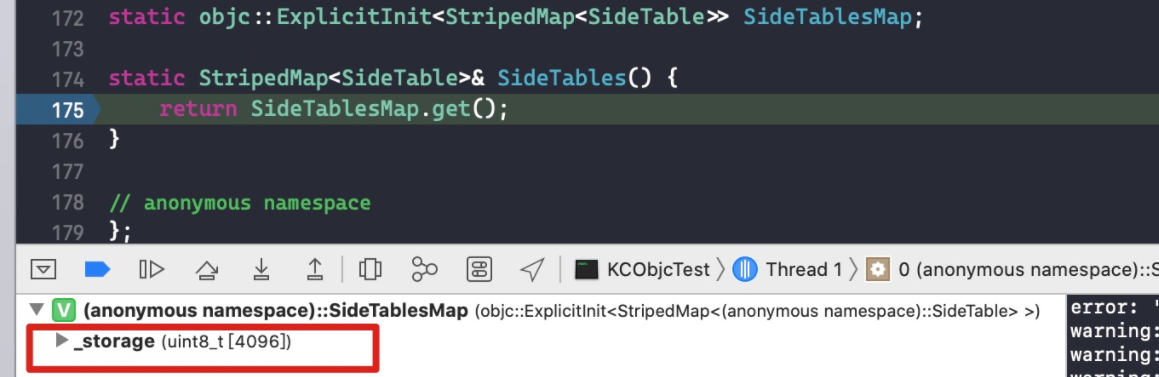
Type &get() { return *reinterpret_cast<Type *>(_storage); } };
ExplicitInit的作用是生成一个模板类型 Type 的实例。alignas(Type) uint8_t _storage[sizeof(Type)];成员变量_storage是一个 sizeof(Type) 长度的 uint8_t 数组,而 uint8_t 占用一个字节,所以实际上_storage的长度跟一个 Type 实例所占用的内存是一样多的。成员函数 Type &get() 将 _storage 数组指针用reinterpret_cast<Type *>强转成了 Type * 类型指针,前面再加一个 *,说明返回的实际上是 Type 实例内存的首地址。而另一个成员函数init用来初始化生成的 Type 实例。
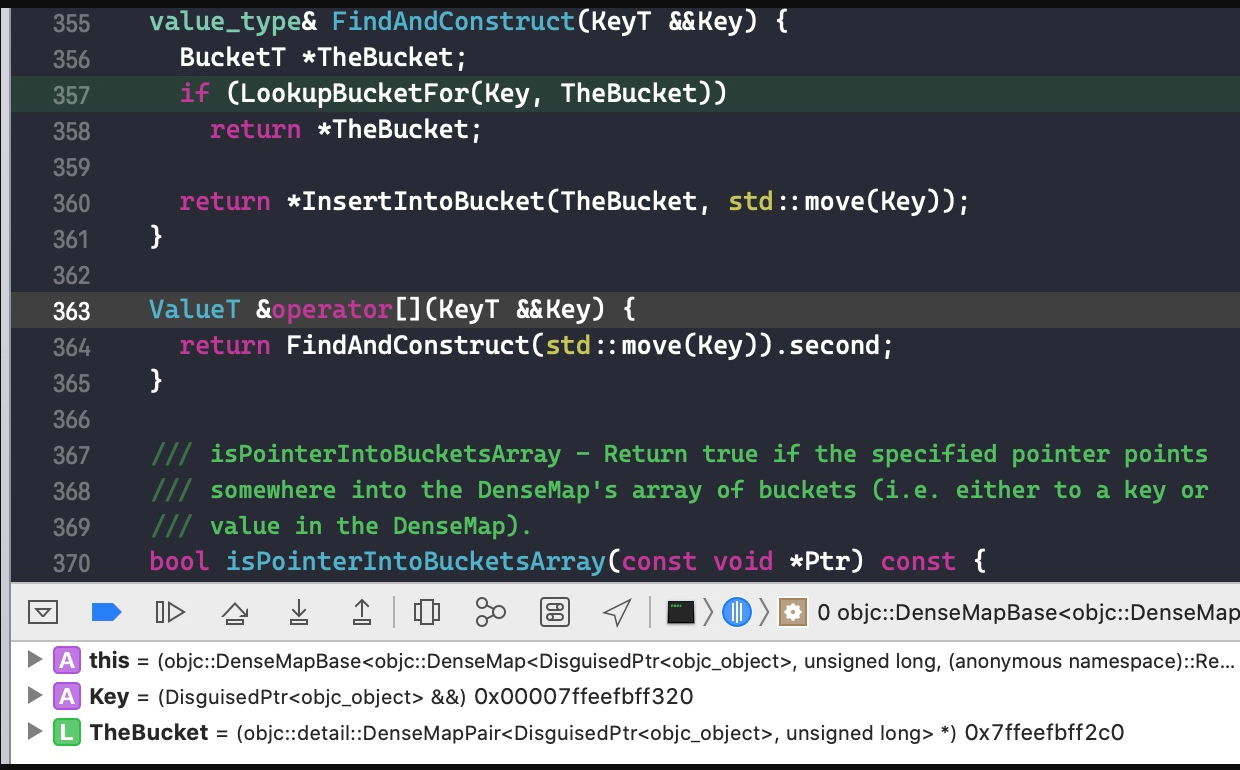
if (NumBuckets == 0) { FoundBucket = nullptr; return false; } // 保存在查找过程中碰到的墓碑 const BucketT *FoundTombstone = nullptr; // DenseMapInfo 的内联函数 getEmptyKey const KeyT EmptyKey = getEmptyKey(); // DenseMapInfo 的内联函数 getTombstoneKey const KeyT TombstoneKey = getTombstoneKey(); assert(!KeyInfoT::isEqual(Val, EmptyKey) && !KeyInfoT::isEqual(Val, TombstoneKey) && "Empty/Tombstone value shouldn't be inserted into map!");
//DenseMapInfo 的静态函数 getHashValue 计算哈希值,并与 NumBuckets-1 进行与运算,得到对应 BucketT 实例的 index unsigned BucketNo = getHashValue(Val) & (NumBuckets-1); // 查找次数 unsigned ProbeAmt = 1; while (true) { const BucketT *ThisBucket = BucketsPtr + BucketNo; // Found Val's bucket? If so, return it. // 找到了对应的 BucketT 实例 if (LLVM_LIKELY(KeyInfoT::isEqual(Val, ThisBucket->getFirst()))) { FoundBucket = ThisBucket; return true; }
// If we found an empty bucket, the key doesn't exist in the set. // Insert it and return the default value. // 如果对应的 bucket 是空的。如果是第一次查找的话则在这个 bucket 里面插入 key 和 value(在InsertIntoBucket函数中执行)。如果不是第一次并且之前找到了墓碑,则使用墓碑bucket插入key和value if (LLVM_LIKELY(KeyInfoT::isEqual(ThisBucket->getFirst(), EmptyKey))) { // If we've already seen a tombstone while probing, fill it in instead // of the empty bucket we eventually probed to. FoundBucket = FoundTombstone ? FoundTombstone : ThisBucket; return false; }
// If this is a tombstone, remember it. If Val ends up not in the map, we // prefer to return it than something that would require more probing. // Ditto for zero values. // 如果找到一个墓碑,则使用 FoundTombstone 将这个墓碑记录下来 if (KeyInfoT::isEqual(ThisBucket->getFirst(), TombstoneKey) && !FoundTombstone) FoundTombstone = ThisBucket; // Remember the first tombstone found. // 如果 FoundTombstone 为空并且 对应的 bucket 的 second 是 0,则用FoundTombstone保存下这个bucket if (ValueInfoT::isPurgeable(ThisBucket->getSecond()) && !FoundTombstone) FoundTombstone = ThisBucket;
// Otherwise, it's a hash collision or a tombstone, continue quadratic // probing. // 如果查找次数多余 NumBuckets ,则报错 if (ProbeAmt > NumBuckets) { FatalCorruptHashTables(BucketsPtr, NumBuckets); } // 重新计算 BucketNo,重新查找 BucketNo += ProbeAmt++; BucketNo &= (NumBuckets-1); } }
template <typename LookupKeyT> BucketT *InsertIntoBucketImpl(const KeyT &Key, const LookupKeyT &Lookup, BucketT *TheBucket) { // If the load of the hash table is more than 3/4, or if fewer than 1/8 of // the buckets are empty (meaning that many are filled with tombstones), // grow the table. // // The later case is tricky. For example, if we had one empty bucket with // tons of tombstones, failing lookups (e.g. for insertion) would have to // probe almost the entire table until it found the empty bucket. If the // table completely filled with tombstones, no lookup would ever succeed, // causing infinite loops in lookup. unsigned NewNumEntries = getNumEntries() + 1; unsigned NumBuckets = getNumBuckets(); // 当 buckets 数组已经使用了超过 3/4 或者 空bucket的数量小于 1/8,则增加 buckets 数组的长度。 if (LLVM_UNLIKELY(NewNumEntries * 4 >= NumBuckets * 3)) { // 扩增原来的 NumBuckets,新的 buckets 长度为旧的两倍,长度至少为 4。新的 buckets 生成后将旧数组里面的数据转移过去,并且旧数组删除 this->grow(NumBuckets * 2); // 因为重新生成了 buckets 数组,所以需要使用LookupBucketFor重新查找对应bucket,并用指针 TheBucket 指向 LookupBucketFor(Lookup, TheBucket); NumBuckets = getNumBuckets(); } else if (LLVM_UNLIKELY(NumBuckets-(NewNumEntries+getNumTombstones()) <= NumBuckets/8)) { this->grow(NumBuckets); LookupBucketFor(Lookup, TheBucket); } ASSERT(TheBucket);
// Only update the state after we've grown our bucket space appropriately // so that when growing buckets we have self-consistent entry count. // If we are writing over a tombstone or zero value, remember this. if (KeyInfoT::isEqual(TheBucket->getFirst(), getEmptyKey())) { // Replacing an empty bucket. // 使用空bucket,NumEntries + 1 incrementNumEntries(); } else if (KeyInfoT::isEqual(TheBucket->getFirst(), getTombstoneKey())) { // Replacing a tombstone. // 使用墓碑 bucket,NumEntries + 1, NumTombstones - 1 incrementNumEntries(); decrementNumTombstones(); } else { // we should be purging a zero. No accounting changes. // 如果 second 等于 0,则析构 second ASSERT(ValueInfoT::isPurgeable(TheBucket->getSecond())); TheBucket->getSecond().~ValueT(); }
注意:当一个对象创建后它的引用计数为 1,但是 isa 指针里的引用计数还是 0。因为初始化的时候并没有对引用计数进行操作。
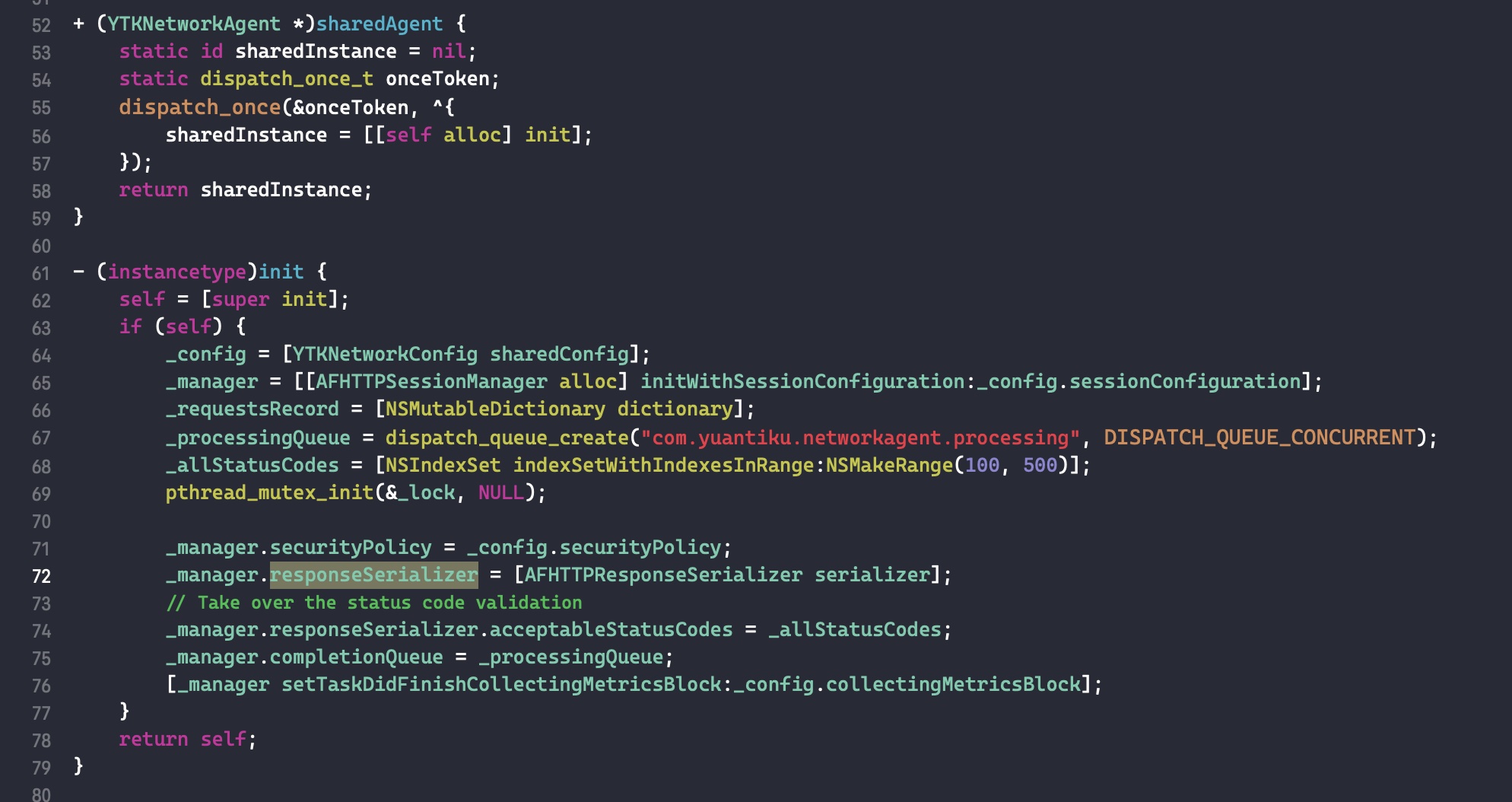
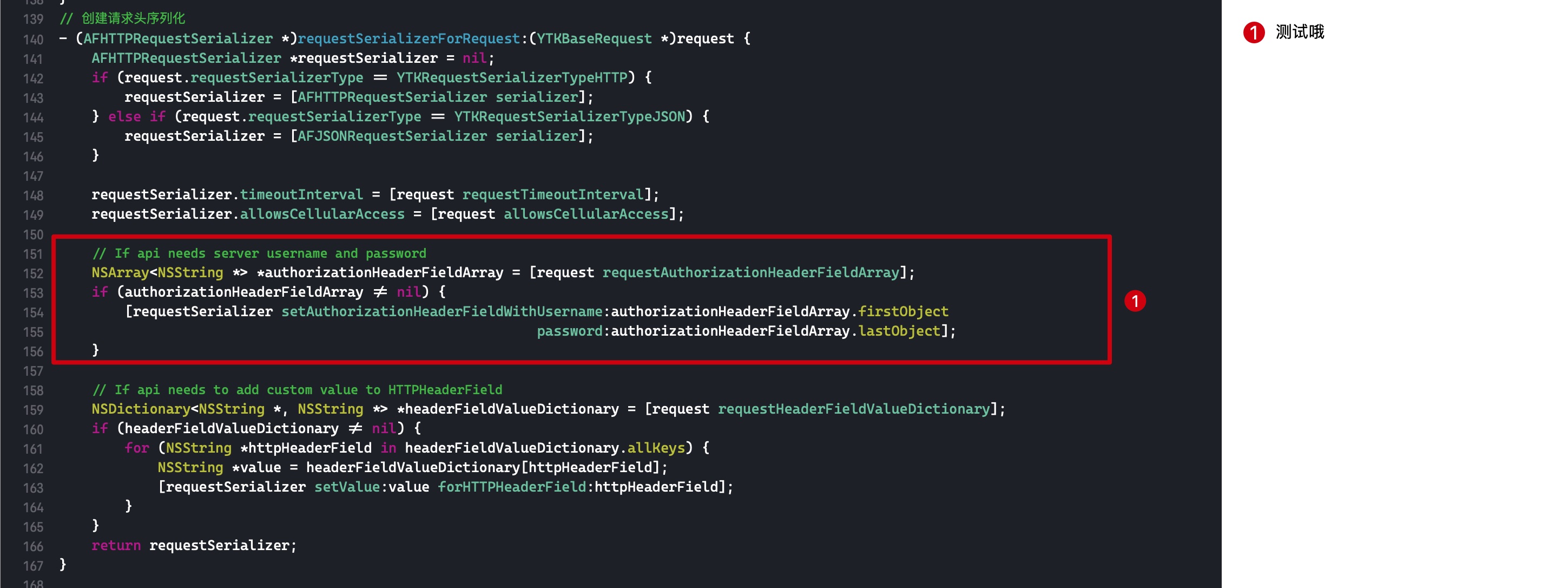
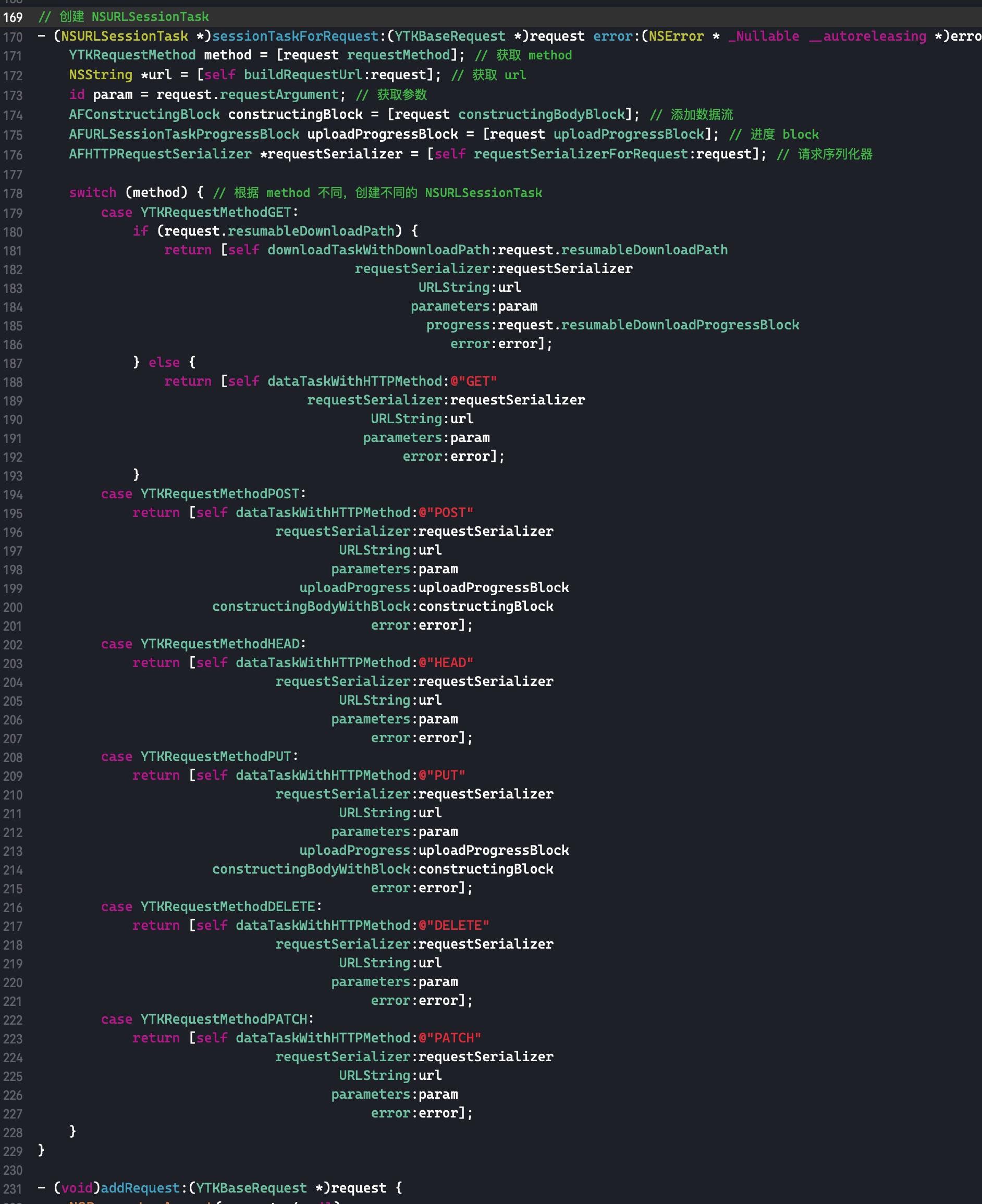
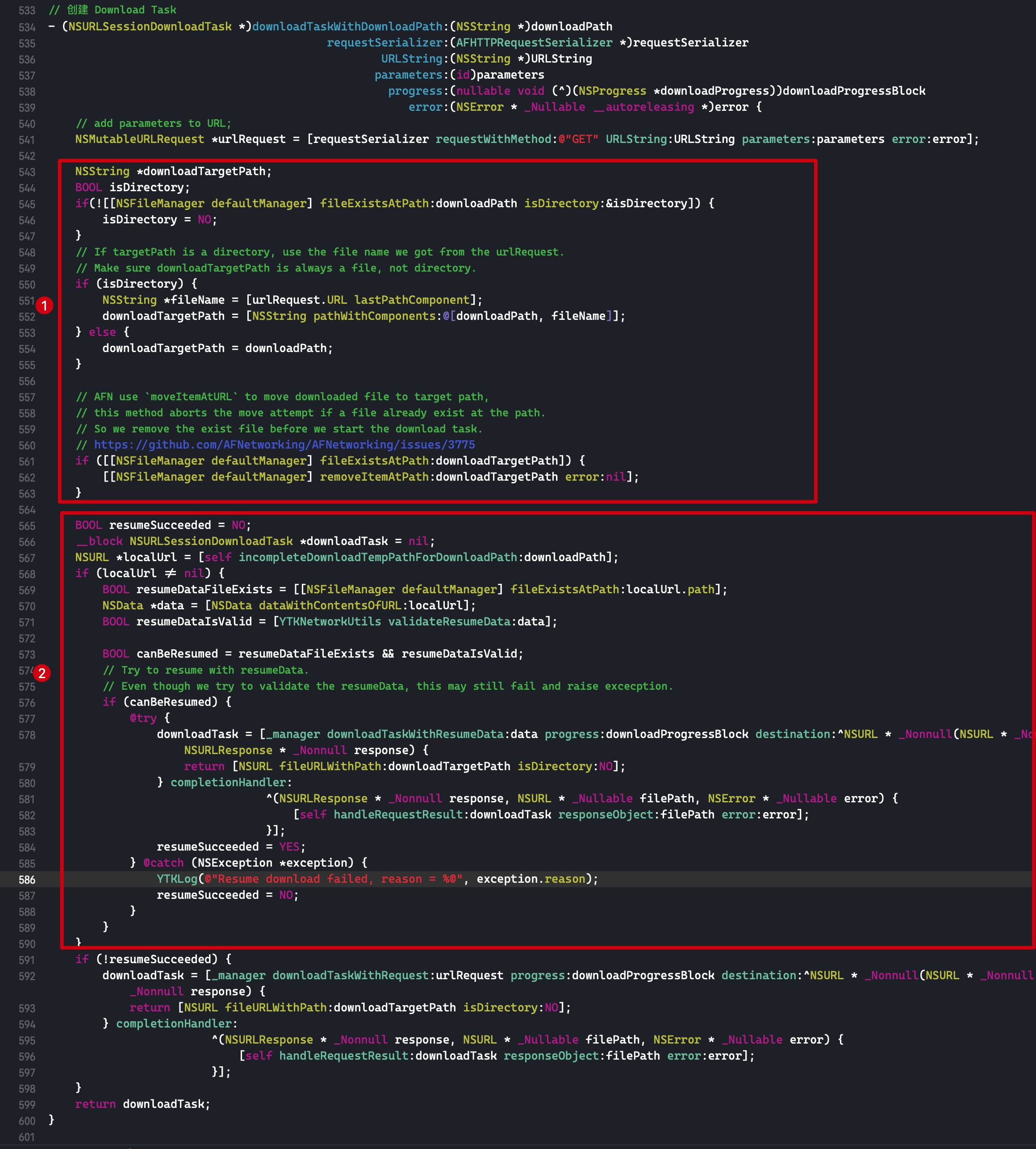
减少引用计数
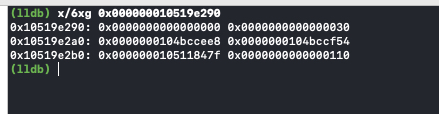
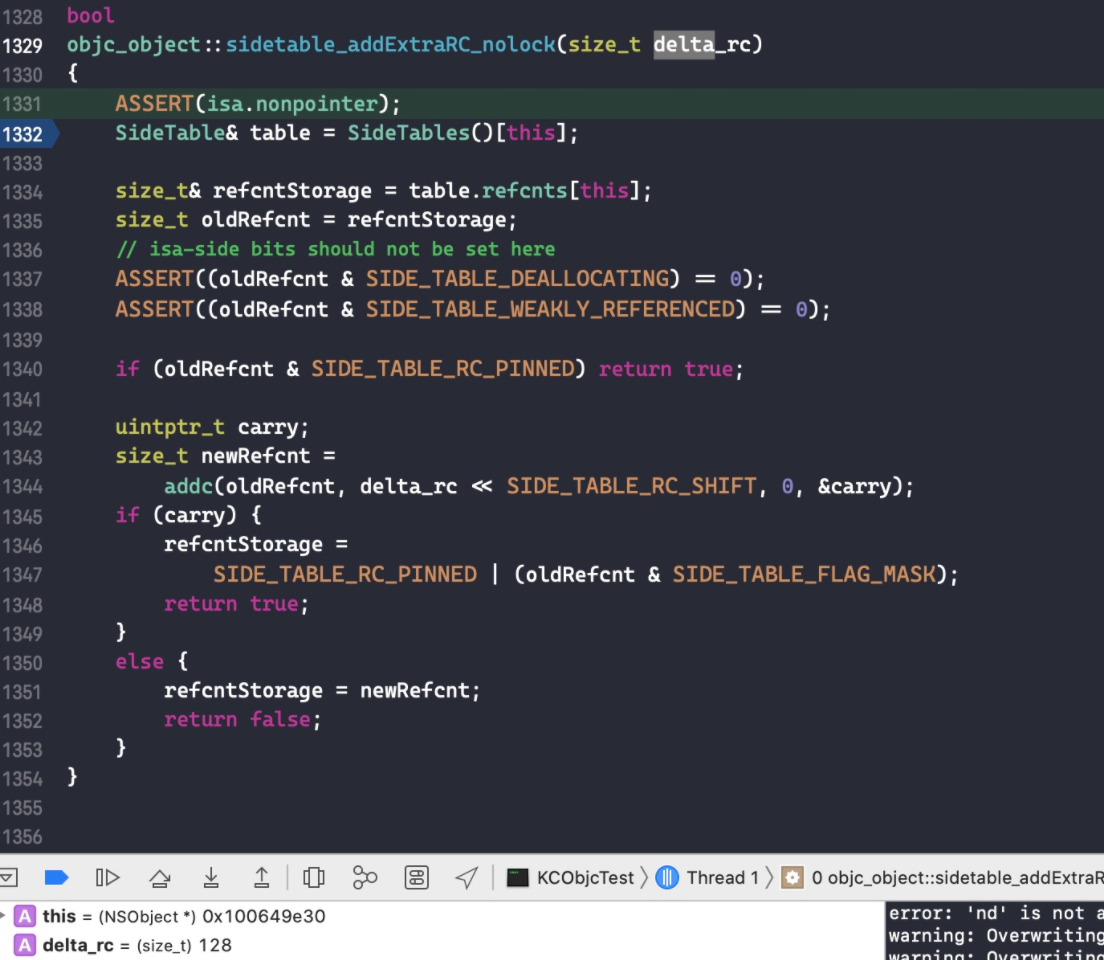
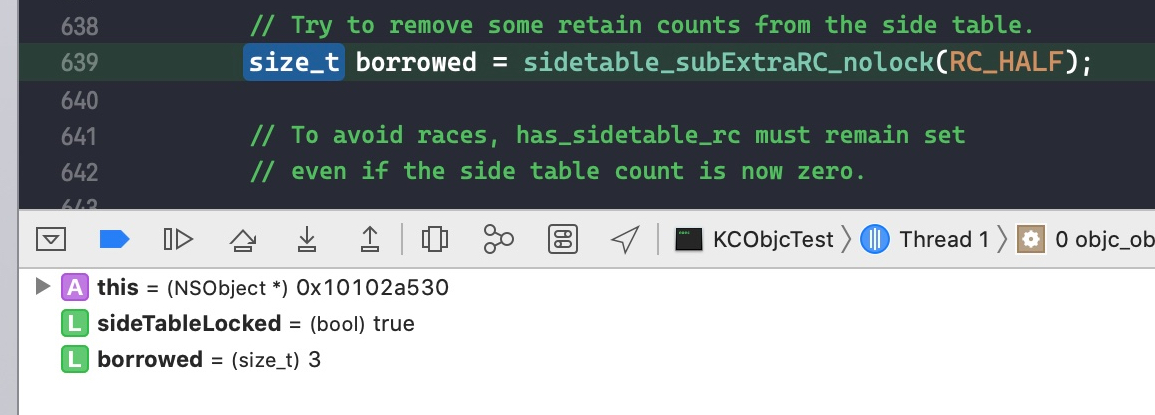
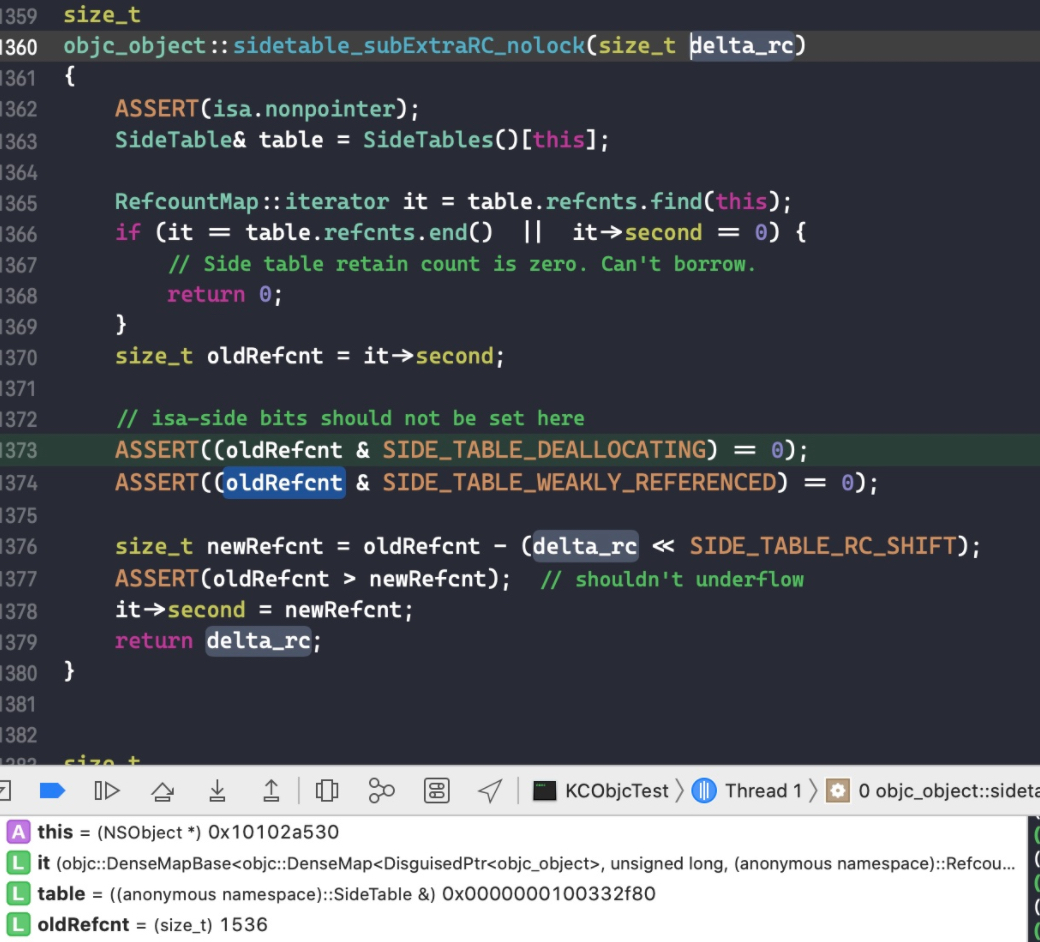
这里我们只讨论有额外引用计数存储在 sidetable,且 isa 指针里面存储的引用计数为 0 时的临界情况。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12
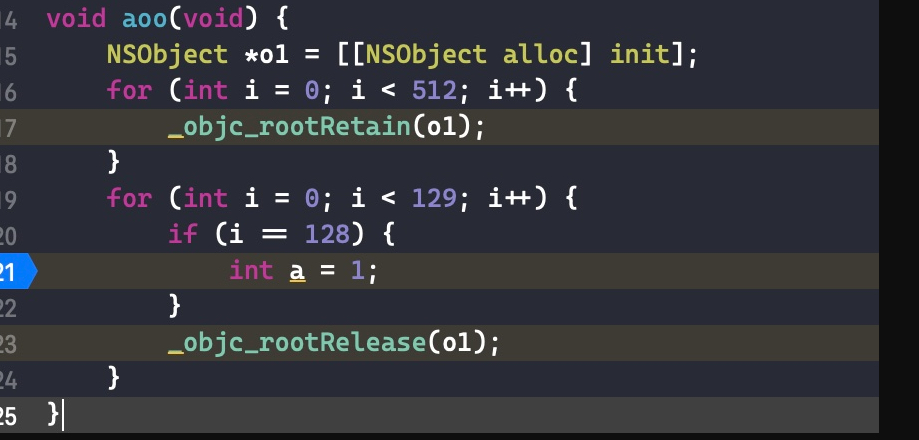
void aoo(void) { NSObject *o1 = [[NSObject alloc] init]; for (int i = 0; i < 512; i++) { _objc_rootRetain(o1); } for (int i = 0; i < 129; i++) { if (i == 128) { int a = 1; } _objc_rootRelease(o1); } }
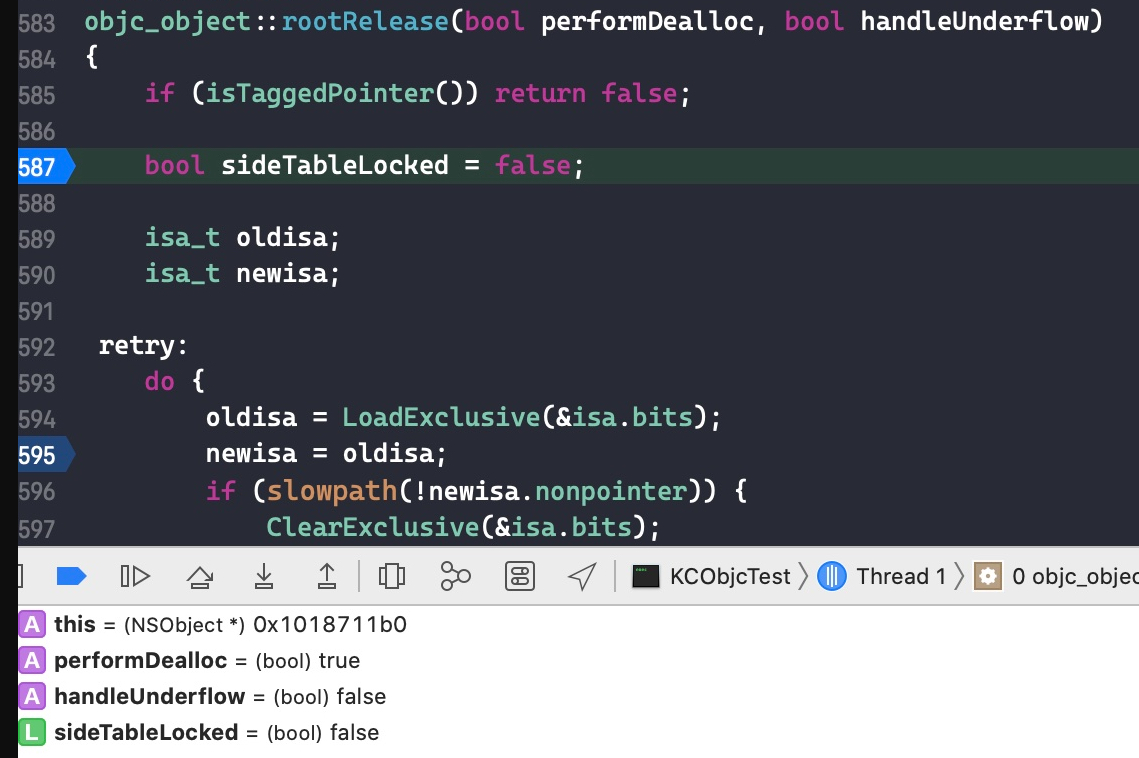
在代码int a = 1;处打个断点,此时 isa 保存的引用计数为 0。一直 step over,直到跳转到objc_object::rootRelease(bool performDealloc, bool handleUnderflow)函数。